Towards Unified Multi-granularity Text Detection with Interactive Attention
{kind=link}
Abstract
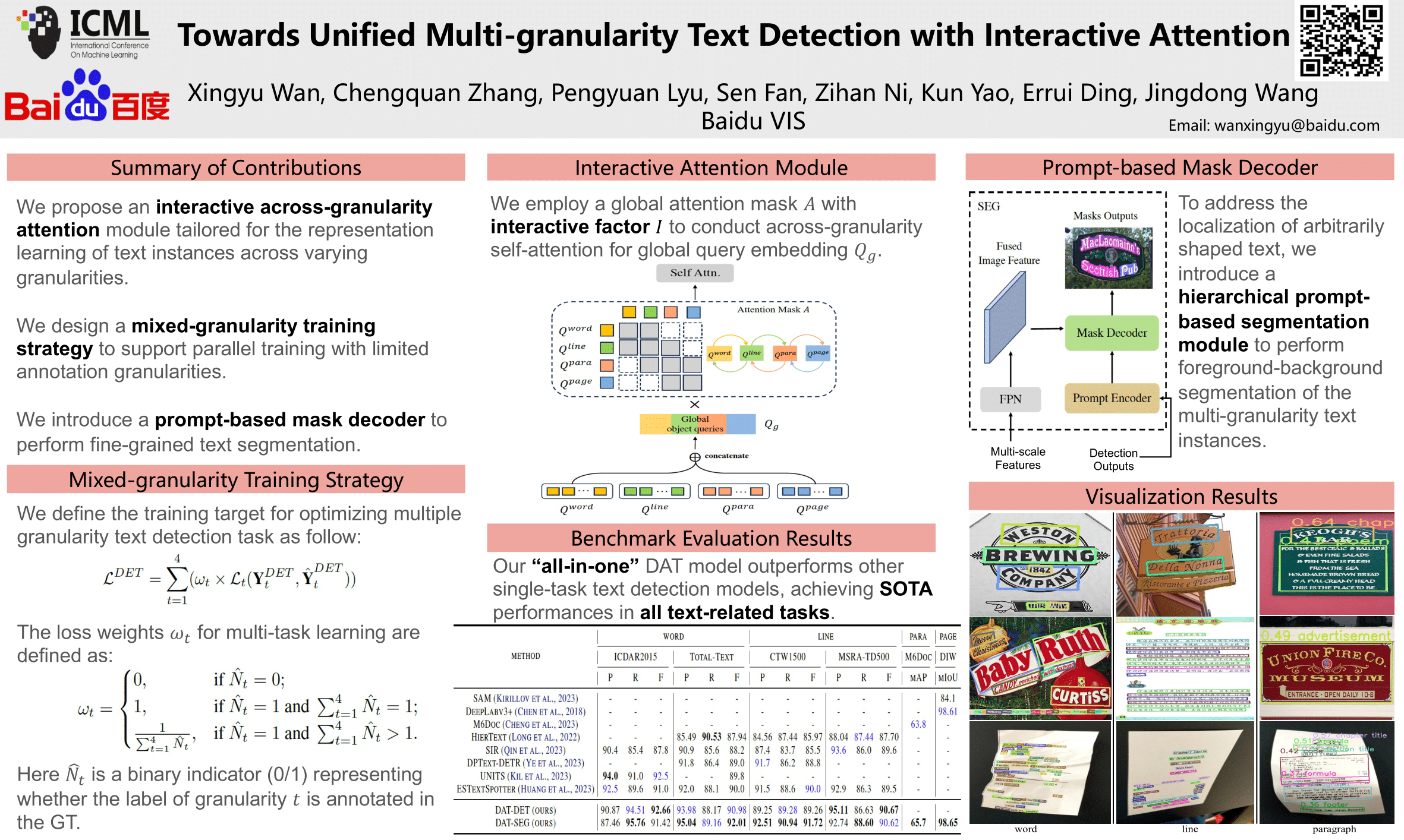
Existing OCR engines or document image analysis systems typically rely on training separate models for text detection in varying scenarios and granularities, leading to significant computational complexity and resource demands. In this paper, we introduce "Detect Any Text" (DAT), an advanced paradigm that seamlessly unifies scene text detection, layout analysis, and document page detection into a cohesive, end-to-end model. This design enables DAT to efficiently manage text instances at different granularities, including word, line, paragraph and page. A pivotal innovation in DAT is the across-granularity interactive attention module, which significantly enhances the representation learning of text instances at varying granularities by correlating structural information across different text queries. As a result, it enables the model to achieve mutually beneficial detection performances across multiple text granularities. Additionally, a prompt-based segmentation module refines detection outcomes for texts of arbitrary curvature and complex layouts, thereby improving DAT's accuracy and expanding its real-world applicability. Experimental results demonstrate that DAT achieves state-of-the-art performances across a variety of text-related benchmarks, including multi-oriented/arbitrarily-shaped scene text detection, document layout analysis and page detection tasks.