Fault Tolerant ML: Efficient Meta-Aggregation and Synchronous Training
{kind=link}
Abstract
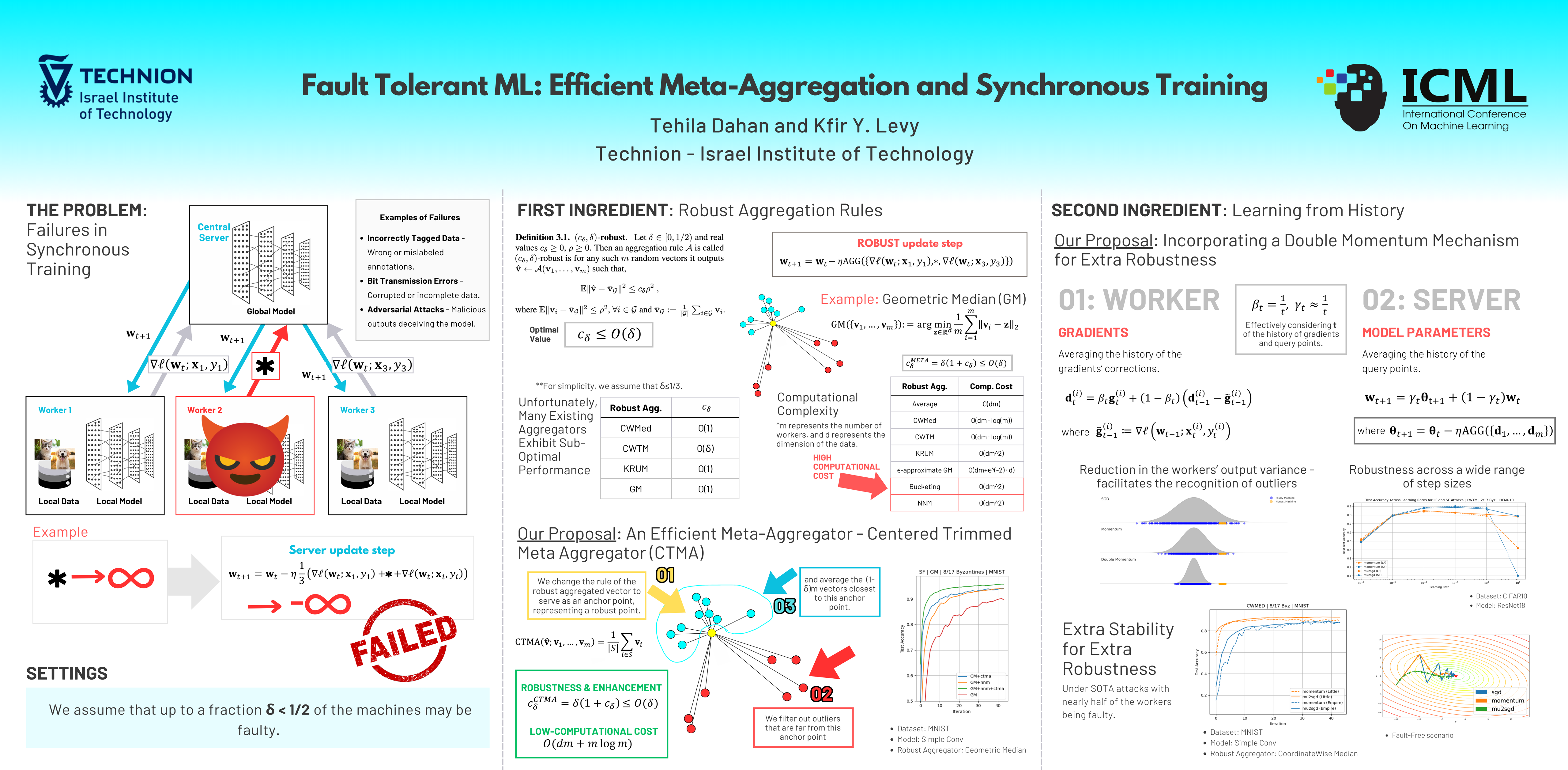
In this paper, we investigate the challenging framework of Byzantine-robust training in distributed machine learning (ML) systems, focusing on enhancing both efficiency and practicality. As distributed ML systems become integral for complex ML tasks, ensuring resilience against Byzantine failures—where workers may contribute incorrect updates due to malice or error—gains paramount importance. Our first contribution is the introduction of the Centered Trimmed Meta Aggregator (CTMA), an efficient meta-aggregator that upgrades baseline aggregators to optimal performance levels, while requiring low computational demands. Additionally, we propose harnessing a recently developed gradient estimation technique based on a double-momentum strategy within the Byzantine context. Our paper highlights its theoretical and practical advantages for Byzantine-robust training, especially in simplifying the tuning process and reducing the reliance on numerous hyperparameters. The effectiveness of this technique is supported by theoretical insights within the stochastic convex optimization (SCO) framework and corroborated by empirical evidence.