Removing Spurious Concepts from Neural Network Representations via Joint Subspace Estimation
{kind=link}
Abstract
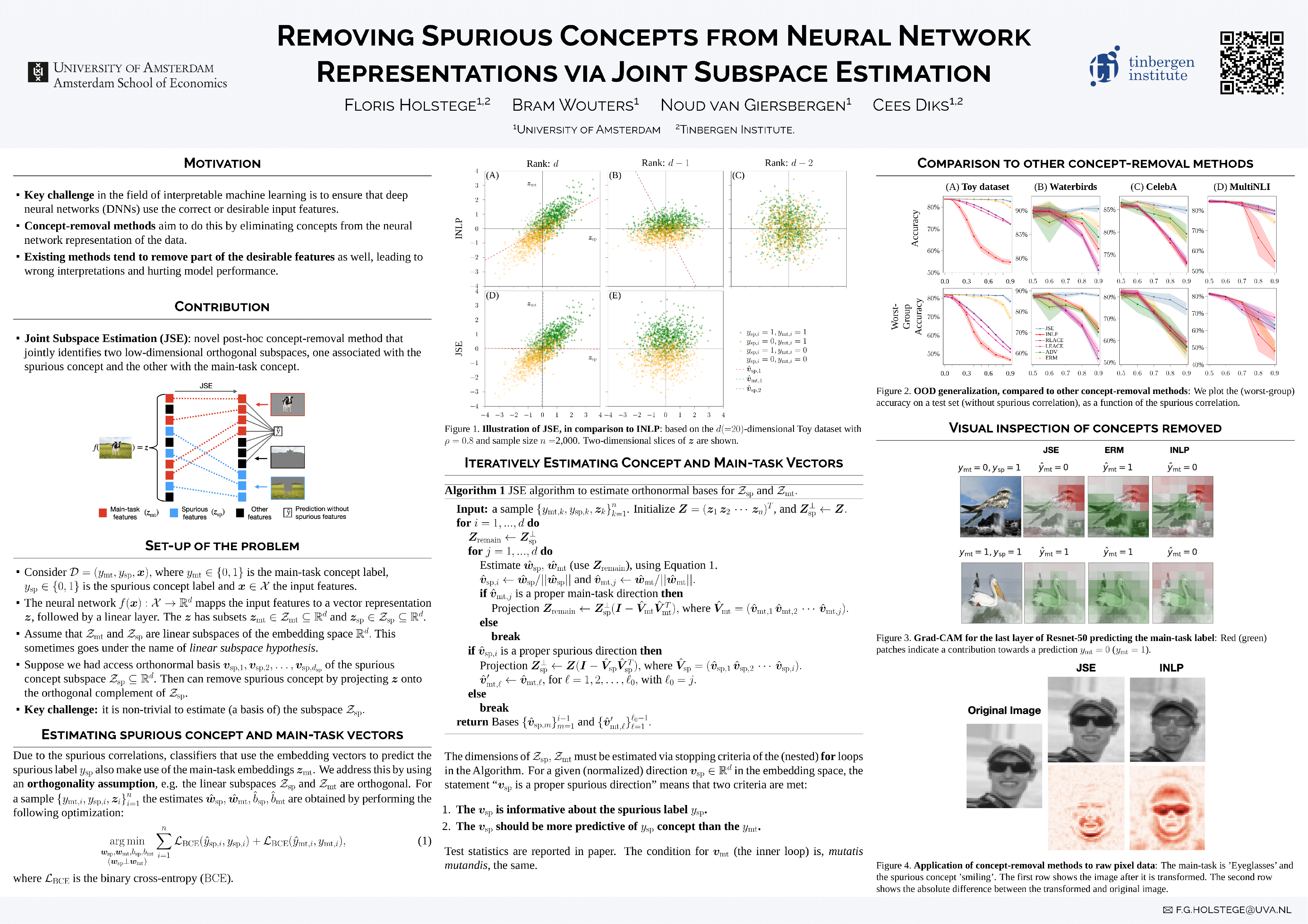
An important challenge in the field of interpretable machine learning is to ensure that deep neural networks (DNNs) use the correct or desirable input features in performing their tasks. Concept-removal methods aim to do this by eliminating concepts that are spuriously correlated with the main task from the neural network representation of the data. However, existing methods tend to be overzealous by inadvertently removing part of the correct or desirable features as well, leading to wrong interpretations and hurting model performance. We propose an iterative algorithm that separates spurious from main-task concepts by jointly estimating two low-dimensional orthogonal subspaces of the neural network representation. By evaluating the algorithm on benchmark datasets from computer vision (Waterbirds, CelebA) and natural language processing (MultiNLI), we show it outperforms existing concept-removal methods in terms of identifying the main-task and spurious concepts, and removing only the latter.