Error Feedback Can Accurately Compress Preconditioners
{kind=link}
Abstract
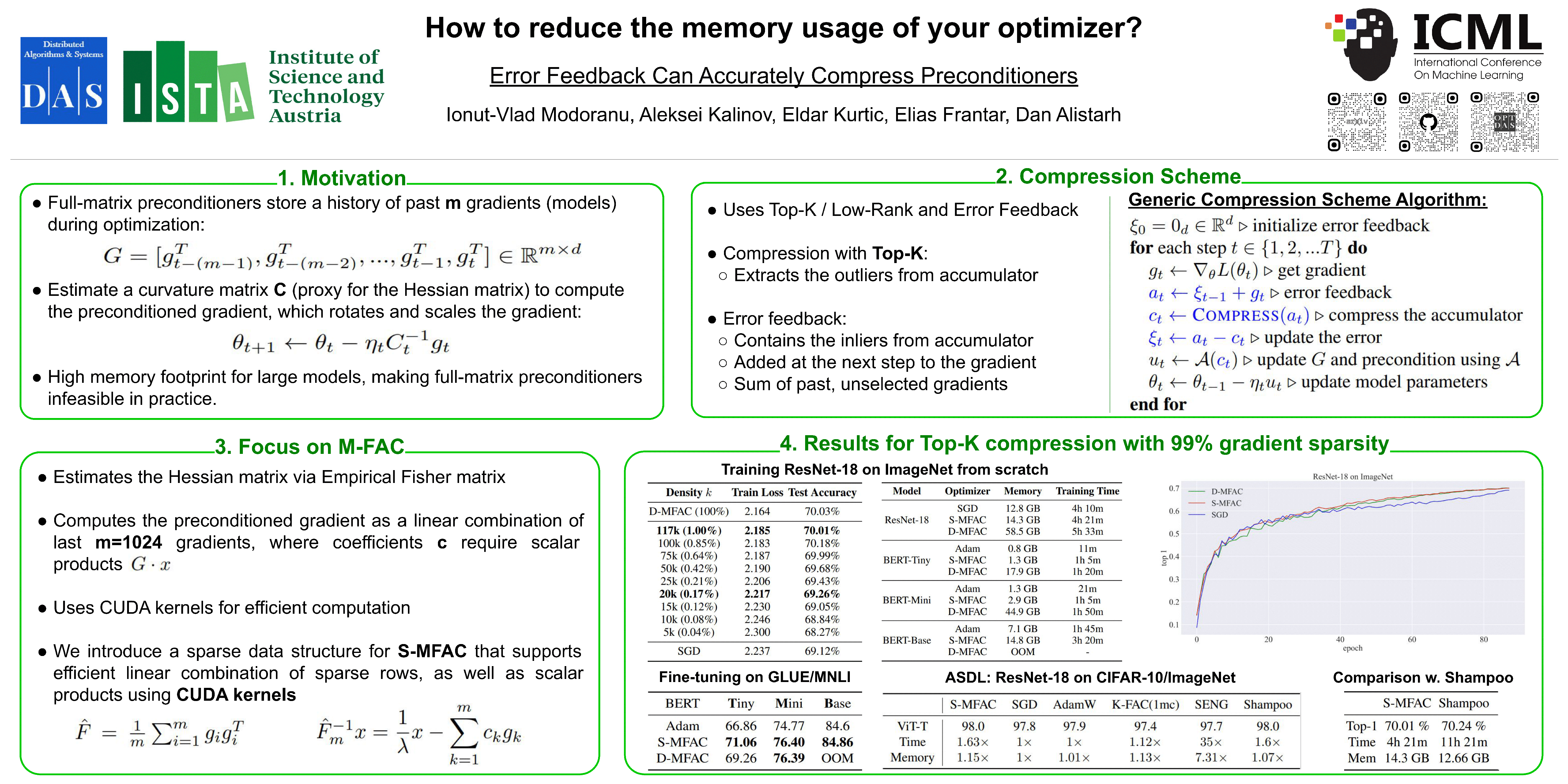
Leveraging second-order information about the loss at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to small-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via a novel and efficient error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression before it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks show that this approach can compress full-matrix preconditioners to up to 99% sparsity without accuracy loss, effectively removing the memory overhead of fullmatrix preconditioners such as GGT and M-FAC.