Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment
{kind=link}
Abstract
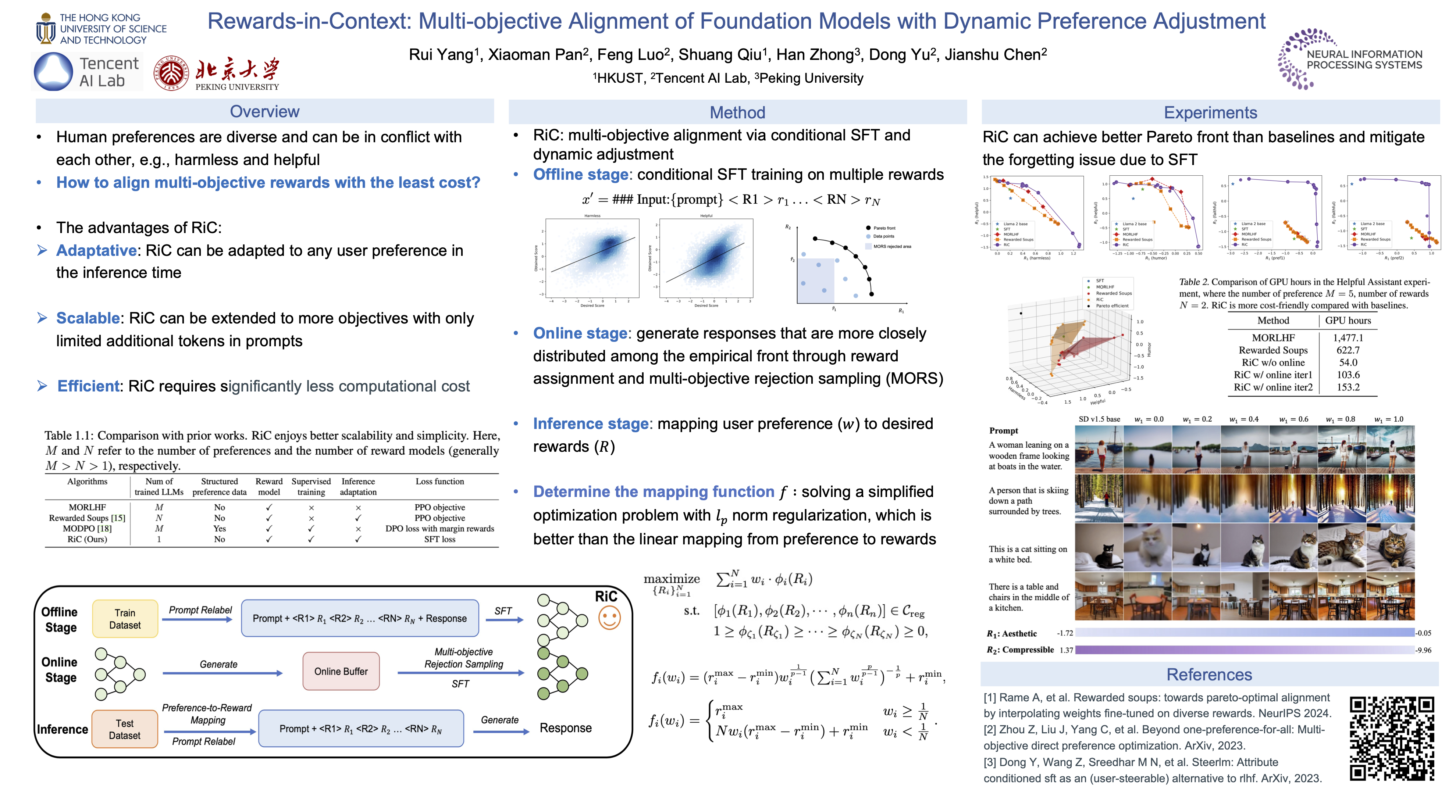
We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and unstable to fine-tune large foundation models using reinforcement learning (RL), and the multi-dimensionality, heterogeneity, and conflicting nature of human preferences further complicate the alignment process. In this paper, we introduce Rewards-in-Context (RiC), which conditions the response of a foundation model on multiple rewards in its prompt context and applies supervised fine-tuning for alignment. The salient features of RiC are simplicity and adaptivity, as it only requires supervised fine-tuning of a single foundation model and supports dynamic adjustment for user preferences during inference time. Inspired by the analytical solution of an abstracted convex optimization problem, our dynamic inference-time adjustment method approaches the Pareto-optimal solution for multiple objectives. Empirical evidence demonstrates the efficacy of our method in aligning both Large Language Models (LLMs) and diffusion models to accommodate diverse rewards with only around 10% GPU hours compared with multi-objective RL baseline.