Reward-Free Kernel-Based Reinforcement Learning
{kind=link}
Abstract
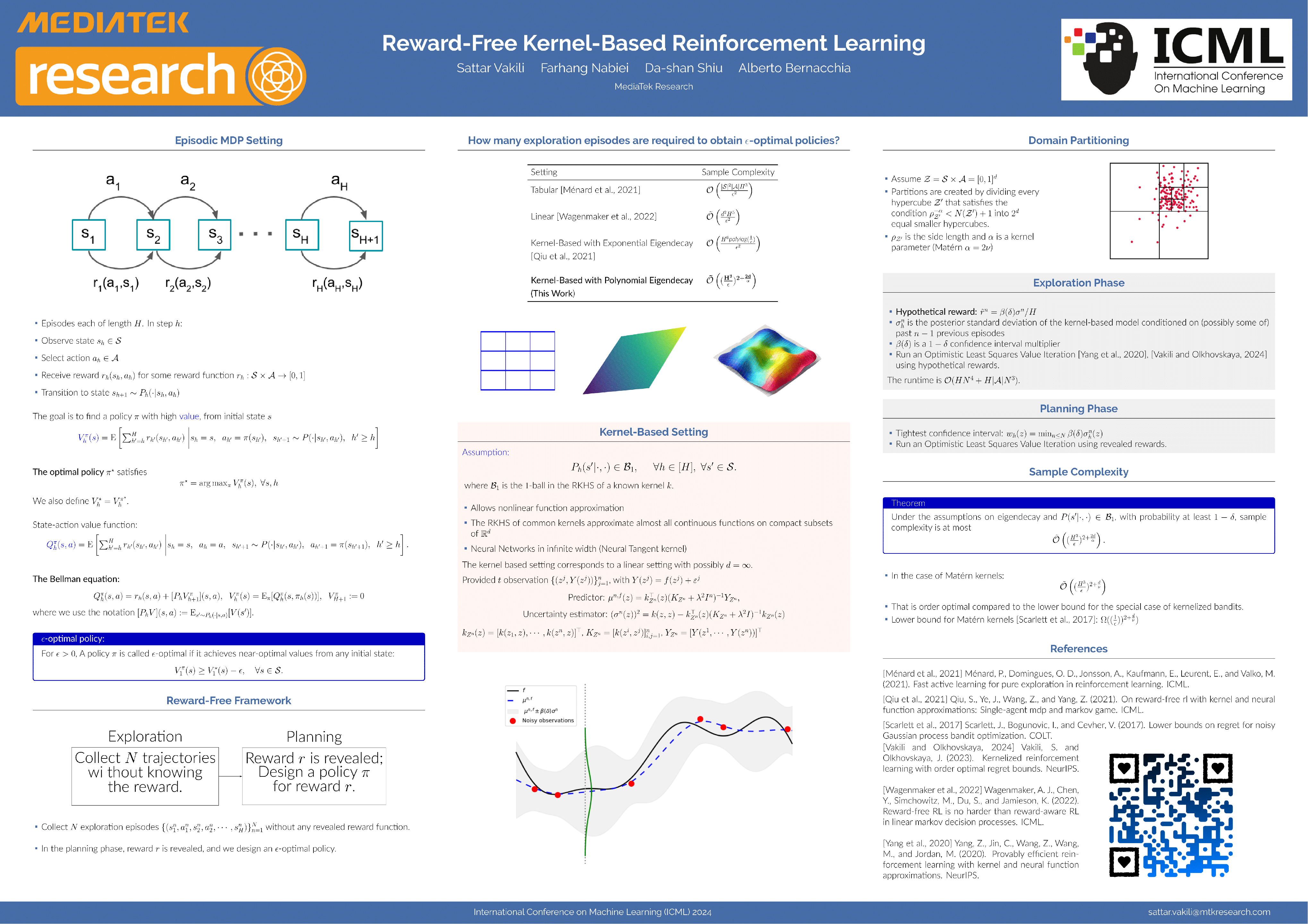
Achieving sample efficiency in Reinforcement Learning (RL) is primarily hinged on the efficient exploration of the underlying environment, but it is still unknown what are the best exploration strategies in different settings. We consider the reward-free RL problem, which operates in two phases: an exploration phase, where the agent gathers exploration trajectories over episodes irrespective of any predetermined reward function, and a subsequent planning phase, where a reward function is introduced. The agent then utilizes the episodes from the exploration phase to calculate a near-optimal policy. Existing algorithms and sample complexities for reward-free RL are limited to tabular, linear or very smooth function approximations, leaving the problem largely open for more general cases. We consider a broad range of kernel-based function approximations, including non-smooth kernels, and propose an algorithm based on adaptive domain partitioning. We show that our algorithm achieves order-optimal sample complexity for a large class of common kernels, which includes Matérn and Neural Tangent kernels.