Enhancing Storage and Computational Efficiency in Federated Multimodal Learning for Large-Scale Models
Zixin Zhang ⋅ Fan Qi ⋅ Changsheng Xu
2024 Poster
{kind=link}
Abstract
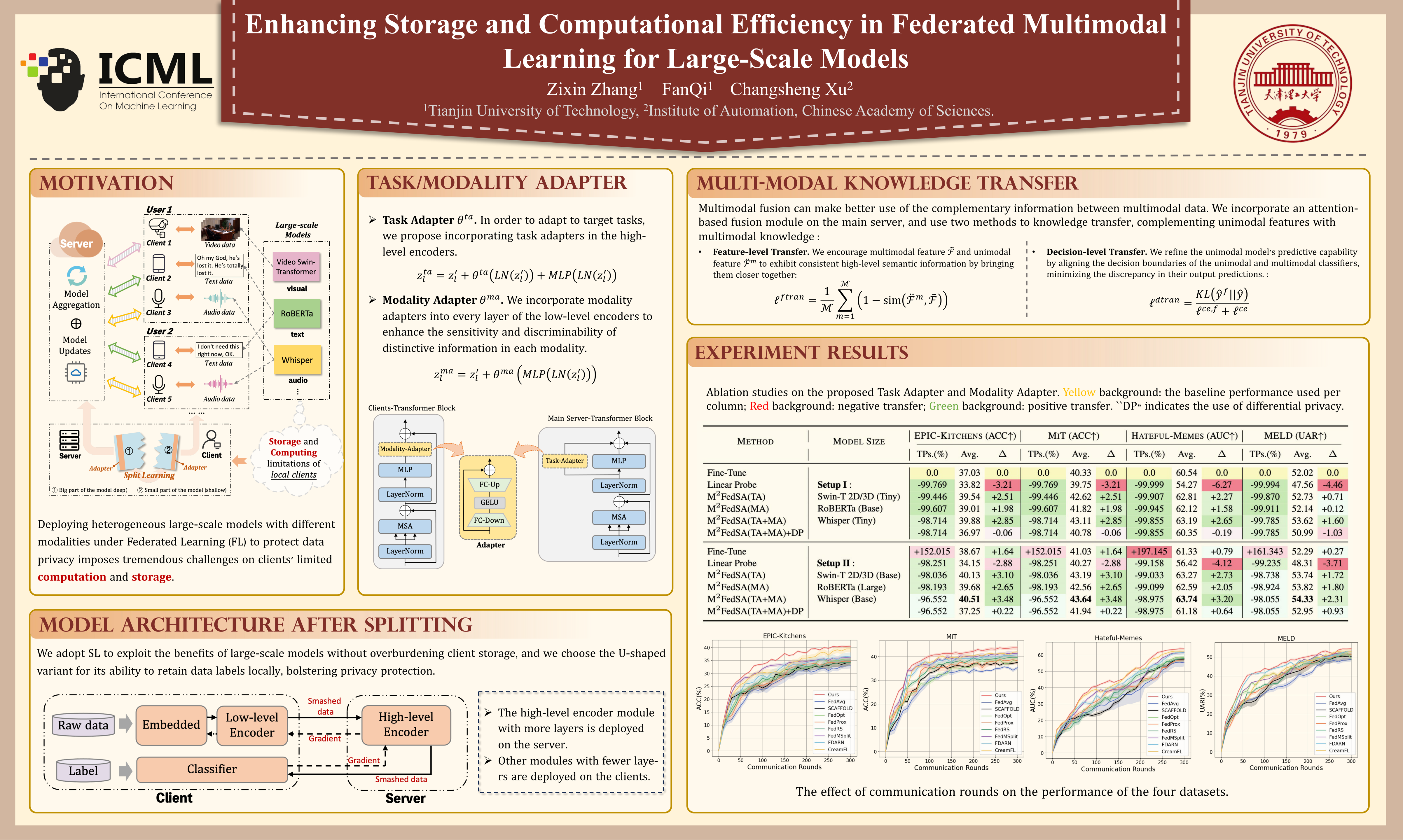
The remarkable generalization of large-scale models has recently gained significant attention in multimodal research. However, deploying heterogeneous large-scale models with different modalities under Federated Learning (FL) to protect data privacy imposes tremendous challenges on clients' limited computation and storage. In this work, we propose M$^2$FedSA to address the above issue. We realize modularized decomposition of large-scale models via Split Learning (SL) and only retain privacy-sensitive modules on clients, alleviating storage overhead. By freezing large-scale models and introducing two specialized lightweight adapters, the models can better focus on task-specific knowledge and enhance modality-specific knowledge, improving the model's adaptability to different tasks while balancing efficiency. In addition, M$^2$FedSA further improves performance by transferring multimodal knowledge to unimodal clients at both the feature and decision levels, which leverages the complementarity of different modalities. Extensive experiments on various multimodal classification tasks validate the effectiveness of our proposed M$^2$FedSA. The code is made available publicly at https://github.com/M2FedSA/M-2FedSA.
Chat is not available.
Successful Page Load