An Information Theoretic Approach to Interaction-Grounded Learning
Xiaoyan Hu ⋅ Farzan Farnia ⋅ Ho-fung Leung
2024 Poster
{kind=link}
Abstract
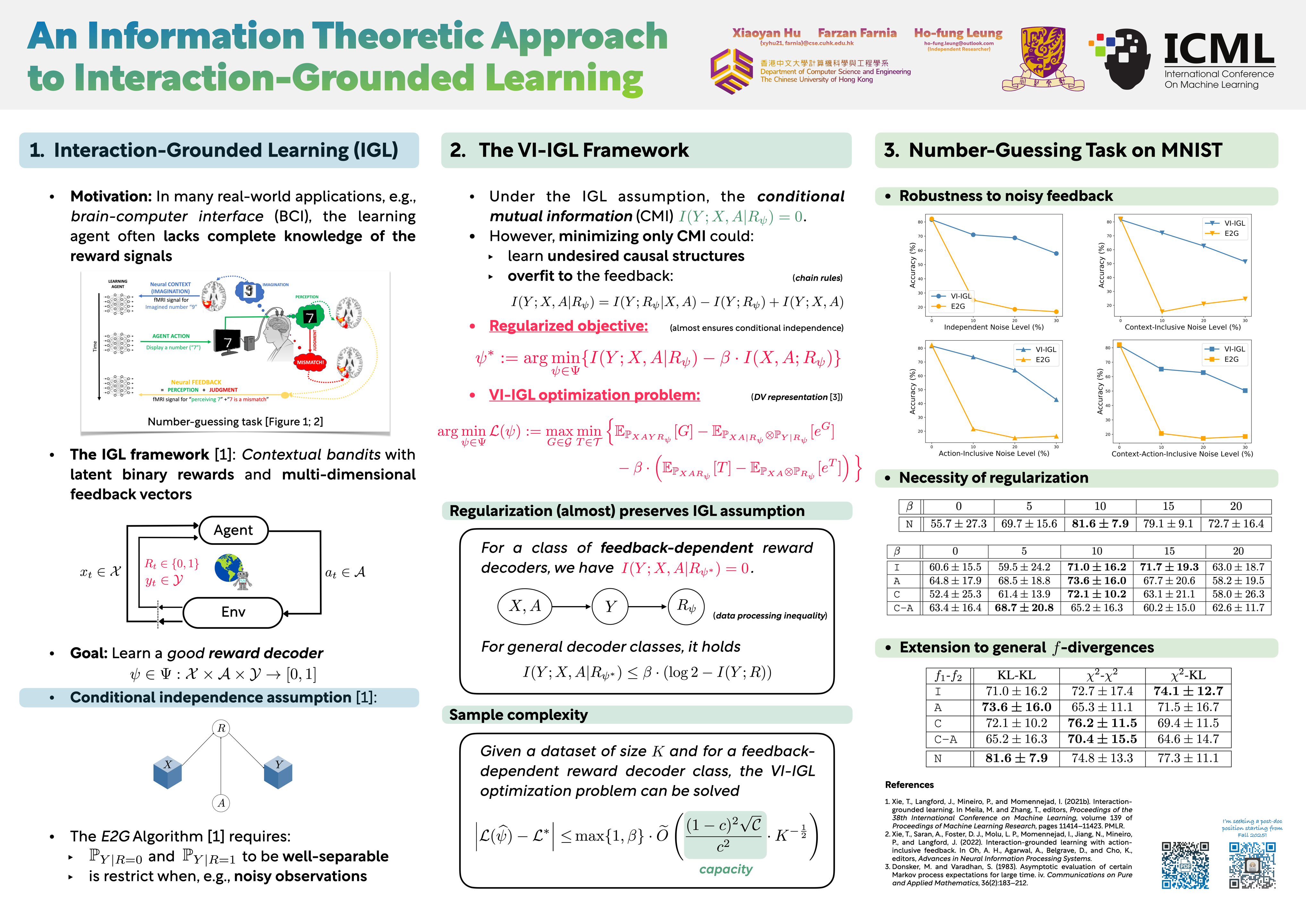
Reinforcement learning (RL) problems where the learner attempts to infer an unobserved reward from some feedback variables have been studied in several recent papers. The setting of Interaction-Grounded Learning (IGL) is an example of such feedback-based reinforcement learning tasks where the learner optimizes the return by inferring latent binary rewards from the interaction with the environment. In the IGL setting, a relevant assumption used in the RL literature is that the feedback variable $Y$ is conditionally independent of the context-action $(X,A)$ given the latent reward $R$. In this work, we propose *Variational Information-based IGL (VI-IGL)* as an information-theoretic method to enforce the conditional independence assumption in the IGL-based RL problem. The VI-IGL framework learns a reward decoder using an information-based objective based on the conditional mutual information (MI) between the context-action $(X,A)$ and the feedback variable $Y$ observed from the environment. To estimate and optimize the information-based terms for the continuous random variables in the RL problem, VI-IGL leverages the variational representation of mutual information and results in a min-max optimization problem. Theoretical analysis shows that the optimization problem can be sample-efficiently solved. Furthermore, we extend the VI-IGL framework to general $f$-Information measures in the information theory literature, leading to the generalized $f$-VI-IGL framework to address the RL problem under the IGL condition. Finally, the empirical results on several reinforcement learning settings indicate an improved performance in comparison to the previous IGL-based RL algorithm.
Chat is not available.
Successful Page Load