Calibration Bottleneck: Over-compressed Representations are Less Calibratable
{kind=link}
Abstract
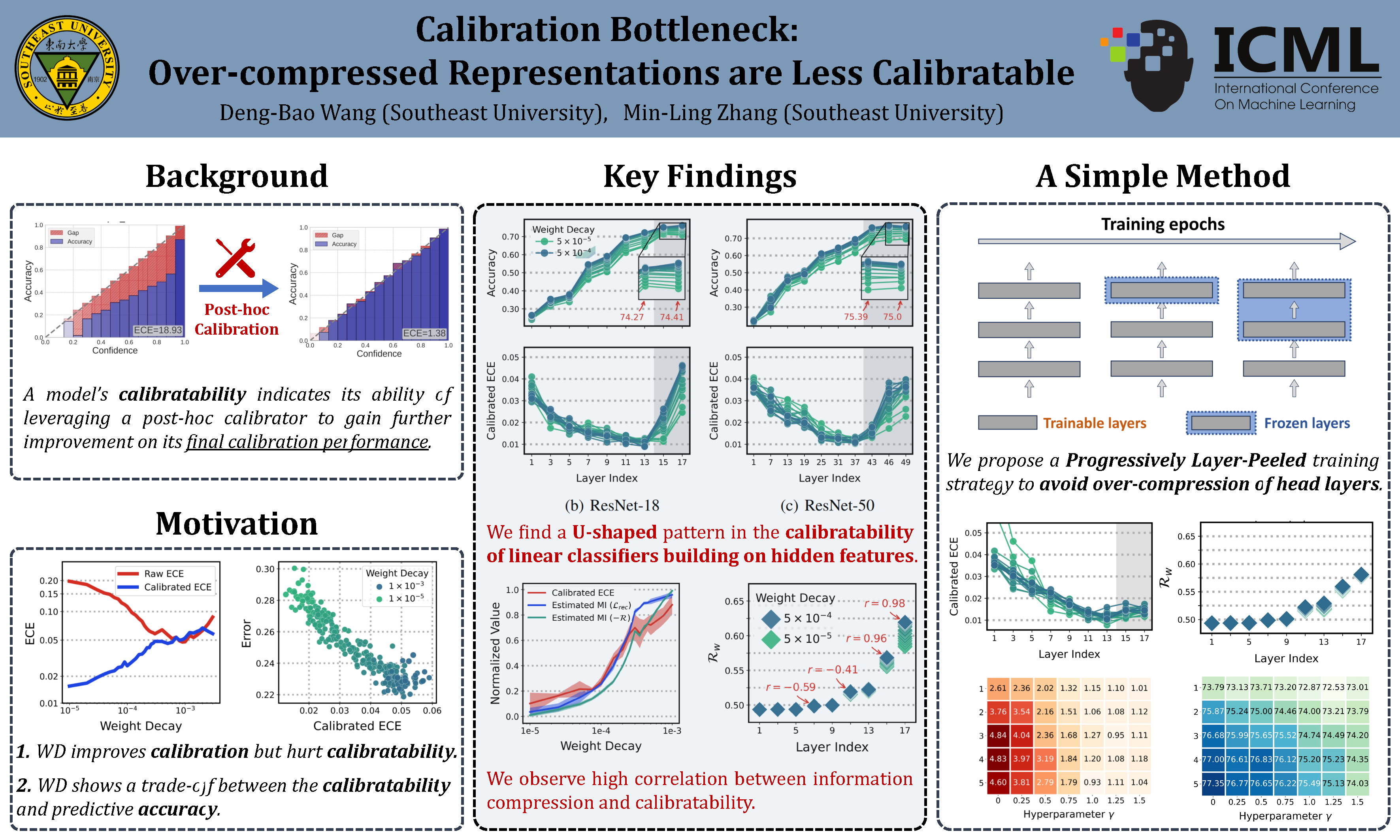
Although deep neural networks have achieved remarkable success, they often exhibit a significant deficiency in reliable uncertainty calibration. This paper focus on model calibratability, which assesses how amenable a model is to be well recalibrated post-hoc. We find that the widely used weight decay regularizer detrimentally affects model calibratability, subsequently leading to a decline in final calibration performance after post-hoc calibration. To identify the underlying causes leading to poor calibratability, we delve into the calibratability of intermediate features across the hidden layers. We observe a U-shaped trend in the calibratability of intermediate features from the bottom to the top layers, which indicates that over-compression of the top representation layers significantly hinders model calibratability. Based on the observations, this paper introduces a weak classifier hypothesis, i.e., given a weak classification head that has not been over-trained, the representation module can be better learned to produce more calibratable features. Consequently, we propose a progressively layer-peeled training (PLP) method to exploit this hypothesis, thereby enhancing model calibratability. Our comparative experiments show the effectiveness of our method, which improves model calibration and also yields competitive predictive performance.