From Vision to Audio and Beyond: A Unified Model for Audio-Visual Representation and Generation
{kind=link}
Abstract
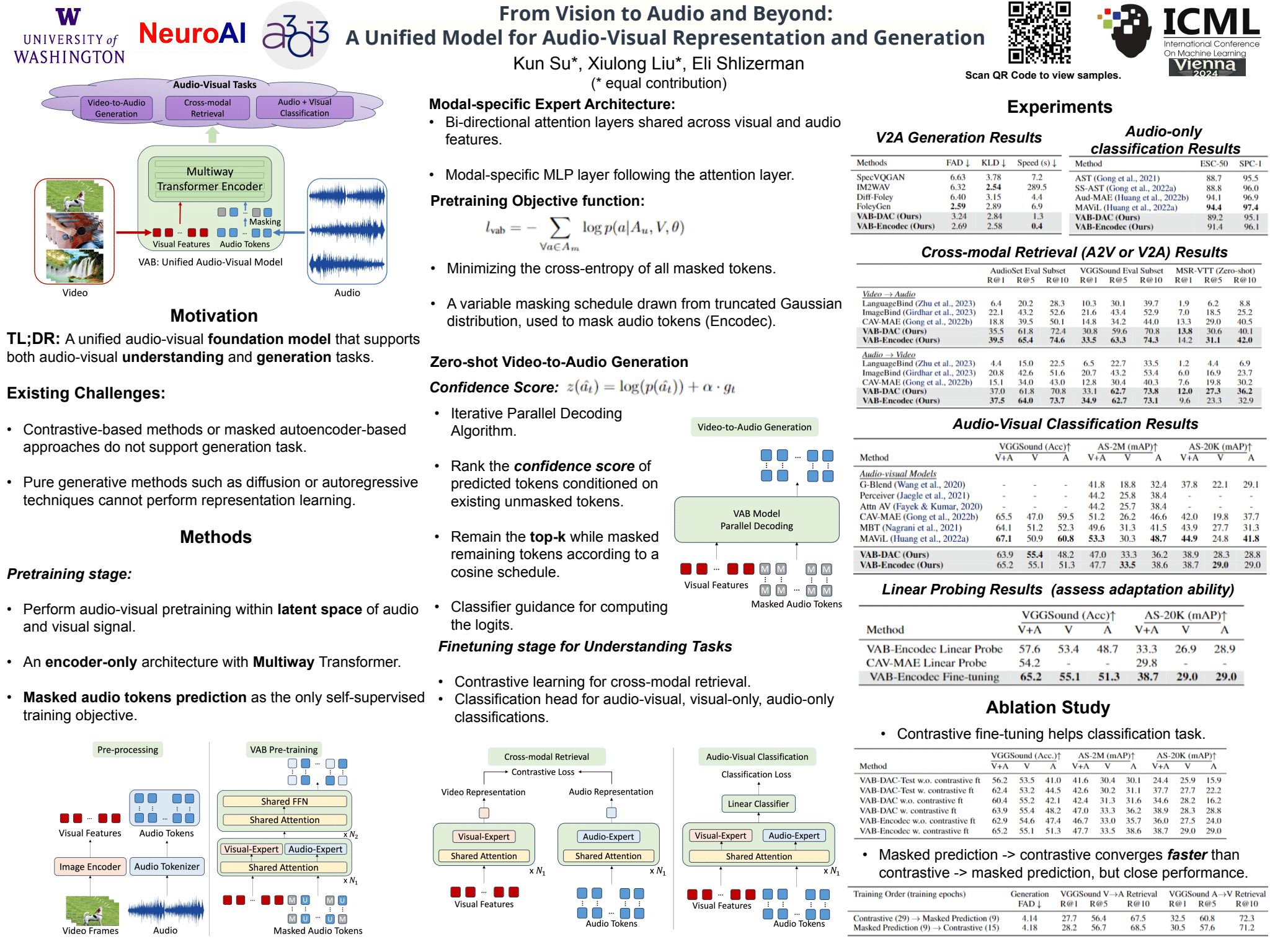
Video encompasses both visual and auditory data, creating a perceptually rich experience where these two modalities complement each other. As such, videos are a valuable type of media for the investigation of the interplay between audio and visual elements. Previous studies of audio-visual modalities primarily focused on either audio-visual representation learning or generative modeling of a modality conditioned on the other, creating a disconnect between these two branches. A unified framework that learns representation and generates modalities has not been developed yet. In this work, we introduce a novel framework called Vision to Audio and Beyond (VAB) to bridge the gap between audio-visual representation learning and vision-to-audio generation. The key approach of VAB is that rather than working with raw video frames and audio data, VAB performs representation learning and generative modeling within latent spaces. In particular, VAB uses a pre-trained audio tokenizer and an image encoder to obtain audio tokens and visual features, respectively. It then performs the pre-training task of visual-conditioned masked audio token prediction. This training strategy enables the model to engage in contextual learning and simultaneous video-to-audio generation. After the pre-training phase, VAB employs the iterative-decoding approach to rapidly generate audio tokens conditioned on visual features. Since VAB is a unified model, its backbone can be fine-tuned for various audio-visual downstream tasks. Our experiments showcase the efficiency of VAB in producing high-quality audio from video, and its capability to acquire semantic audio-visual features, leading to competitive results in audio-visual retrieval and classification.