MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Prajwal K R ⋅ Bowen Shi ⋅ Matthew Le ⋅ Apoorv Vyas ⋅ Andros Tjandra ⋅ Mahi Luthra ⋅ Baishan Guo ⋅ Huiyu Wang ⋅ Triantafyllos Afouras ⋅ David Kant ⋅ Wei-Ning Hsu
2024 Poster
{kind=link}
Abstract
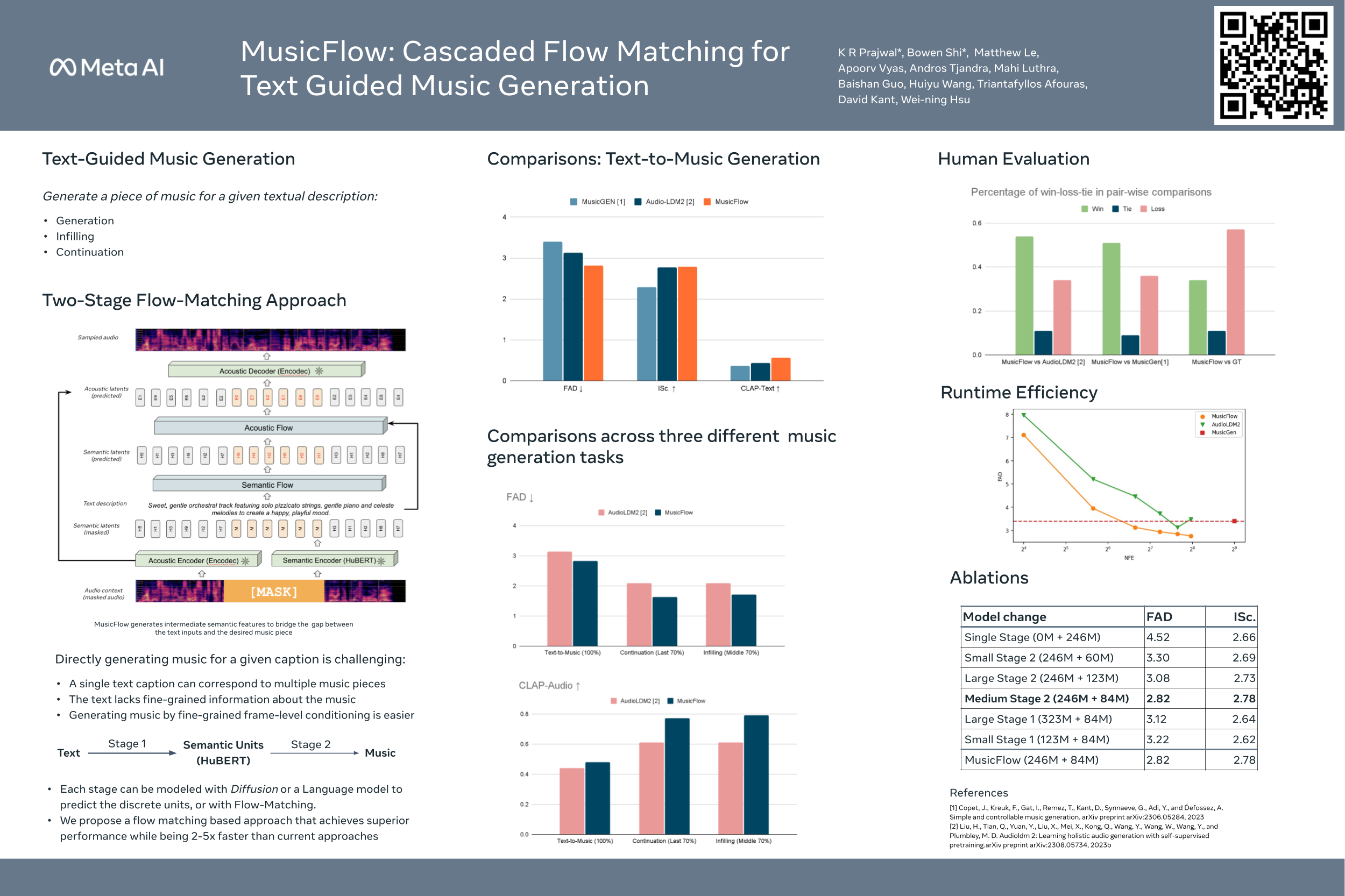
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation.
Chat is not available.
Successful Page Load