PIPER: Primitive-Informed Preference-based Hierarchical Reinforcement Learning via Hindsight Relabeling
Utsav Singh ⋅ Wesley A. Suttle ⋅ Brian Sadler ⋅ Vinay Namboodiri ⋅ Amrit Singh Bedi
2024 Poster
{kind=link}
Abstract
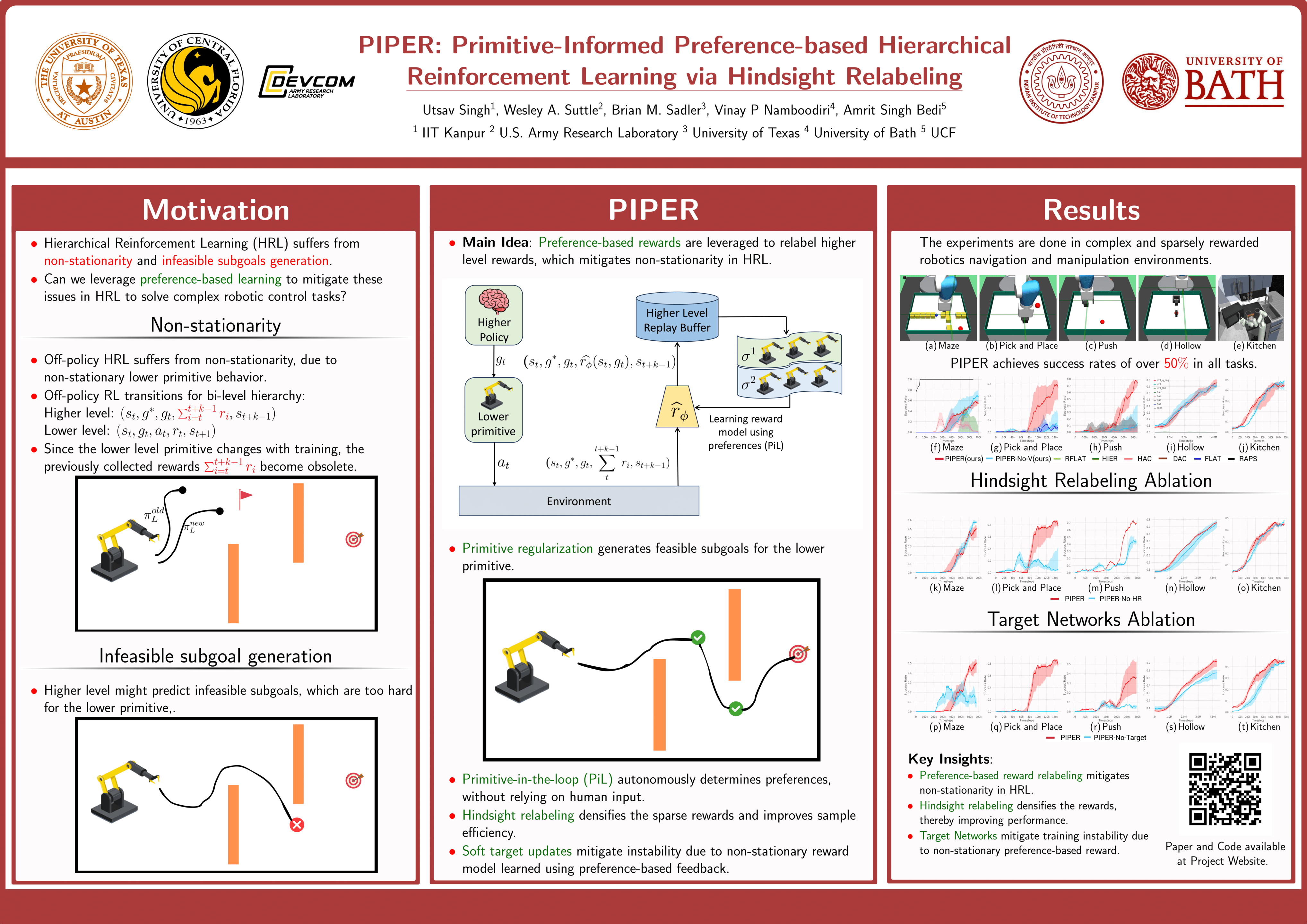
In this work, we introduce PIPER: Primitive-Informed Preference-based Hierarchical reinforcement learning via Hindsight Relabeling, a novel approach that leverages preference-based learning to learn a reward model, and subsequently uses this reward model to relabel higher-level replay buffers. Since this reward is unaffected by lower primitive behavior, our relabeling-based approach is able to mitigate non-stationarity, which is common in existing hierarchical approaches, and demonstrates impressive performance across a range of challenging sparse-reward tasks. Since obtaining human feedback is typically impractical, we propose to replace the human-in-the-loop approach with our primitive-in-the-loop approach, which generates feedback using sparse rewards provided by the environment. Moreover, in order to prevent infeasible subgoal prediction and avoid degenerate solutions, we propose primitive-informed regularization that conditions higher-level policies to generate feasible subgoals for lower-level policies. We perform extensive experiments to show that PIPER mitigates non-stationarity in hierarchical reinforcement learning and achieves greater than 50$\\%$ success rates in challenging, sparse-reward robotic environments, where most other baselines fail to achieve any significant progress.
Chat is not available.
Successful Page Load