Reinformer: Max-Return Sequence Modeling for Offline RL
{kind=link}
Abstract
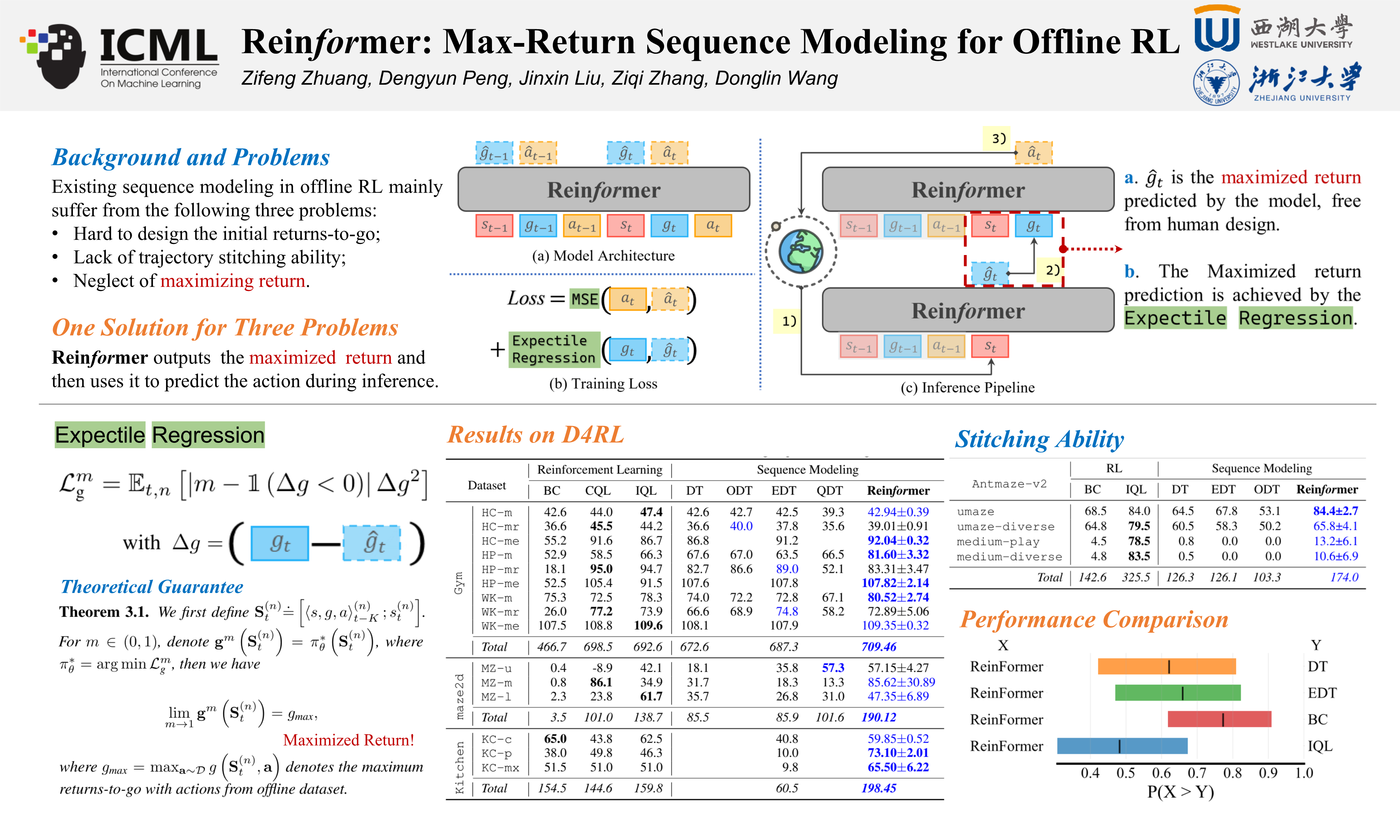
As a data-driven paradigm, offline reinforcement learning (RL) has been formulated as sequence modeling that conditions on the hindsight information including returns, goal or future trajectory. Although promising, this supervised paradigm overlooks the core objective of RL that maximizes the return. This overlook directly leads to the lack of trajectory stitching capability that affects the sequence model learning from sub-optimal data. In this work, we introduce the concept of max-return sequence modeling which integrates the goal of maximizing returns into existing sequence models. We propose Reinforced Transformer (Reinformer), indicating the sequence model is reinforced by the RL objective. Reinformer additionally incorporates the objective of maximizing returns in the training phase, aiming to predict the maximum future return within the distribution. During inference, this in-distribution maximum return will guide the selection of optimal actions. Empirically, Reinformer is competitive with classical RL methods on the D4RL benchmark and outperforms state-of-the-art sequence model particularly in trajectory stitching ability. Code is public at https://github.com/Dragon-Zhuang/Reinformer.