Double Stochasticity Gazes Faster: Snap-Shot Decentralized Stochastic Gradient Tracking Methods
Hao Di ⋅ Haishan Ye ⋅ Xiangyu Chang ⋅ Guang Dai ⋅ Ivor Tsang
2024 Poster
{kind=link}
Abstract
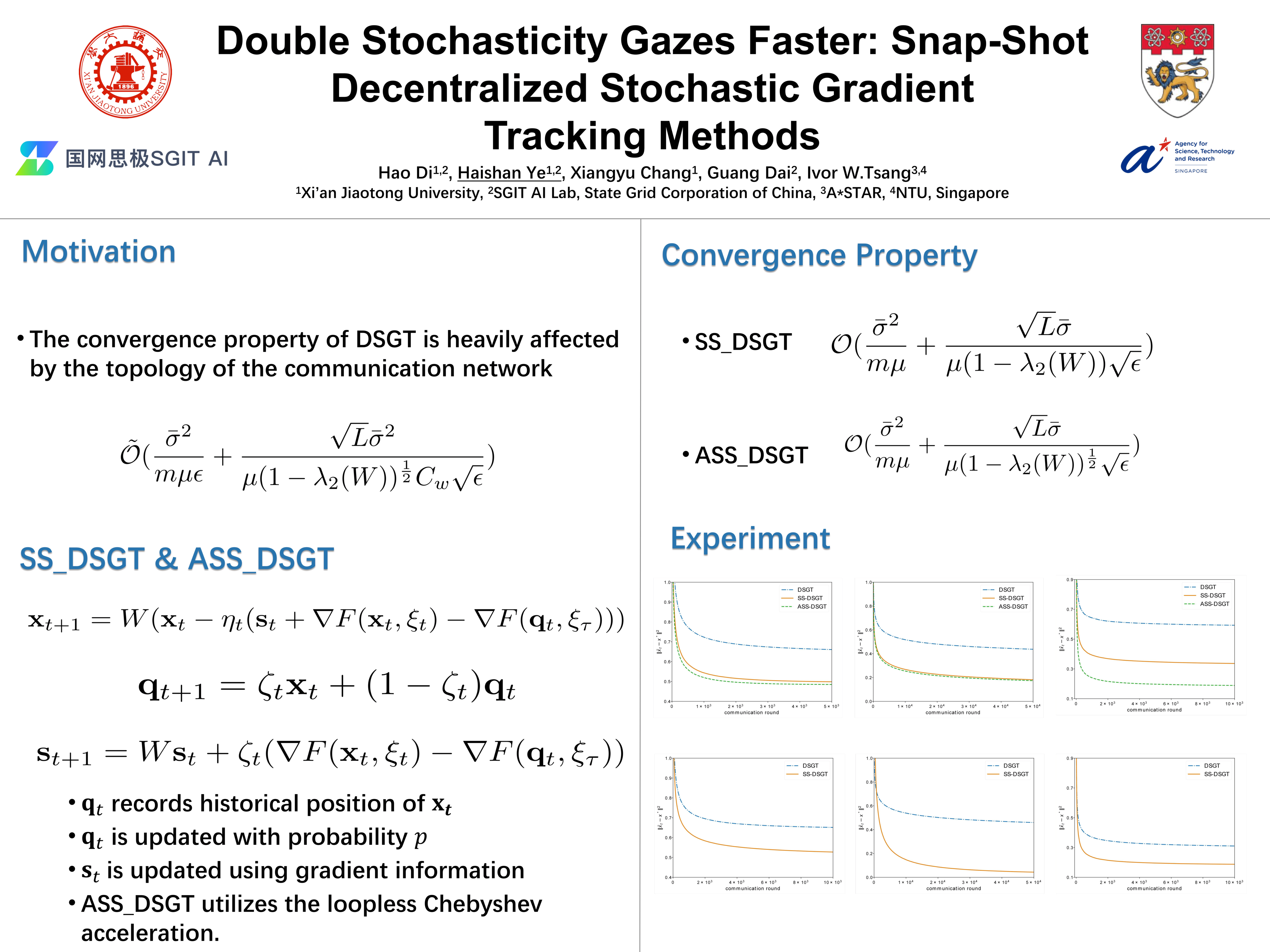
In decentralized optimization, $m$ agents form a network and only communicate with their neighbors, which gives advantages in data ownership, privacy, and scalability. At the same time, decentralized stochastic gradient descent ($\texttt{SGD}$) methods, as popular decentralized algorithms for training large-scale machine learning models, have shown their superiority over centralized counterparts. Distributed stochastic gradient tracking $\texttt{DSGT}$ has been recognized as the popular and state-of-the-art decentralized $\texttt{SGD}$ method due to its proper theoretical guarantees. However, the theoretical analysis of $\texttt{DSGT}$ shows that its iteration complexity is $\tilde{\mathcal{O}} \left(\frac{\bar{\sigma}^2}{m\mu \varepsilon} + \frac{\sqrt{L}\bar{\sigma}}{\mu(1 - \lambda_2(W))^{1/2} C_W \sqrt{\varepsilon} }\right)$, where the doubly stochastic matrix $W$ represents the network topology and $ C_W $ is a parameter that depends on $W$. Thus, it indicates that the convergence property of $\texttt{DSGT}$ is heavily affected by the topology of the communication network. To overcome the weakness of $\texttt{DSGT}$, we resort to the snap-shot gradient tracking skill and propose two novel algorithms, snap-shot $\texttt{DSGT}$ ($\texttt{SS-DSGT}$) and accelerated snap-shot $\texttt{DSGT}$ ($\texttt{ASS-DSGT}$). We further justify that $\texttt{SS-DSGT}$ exhibits a lower iteration complexity compared to $\texttt{DSGT}$ in the general communication network topology. Additionally, $\texttt{ASS-DSGT}$ matches $\texttt{DSGT}$'s iteration complexity $\mathcal{O}\left( \frac{\bar{\sigma}^2}{m\mu \varepsilon} + \frac{\sqrt{L}\bar{\sigma}}{\mu (1 - \lambda_2(W))^{1/2}\sqrt{\varepsilon}} \right)$ under the same conditions as $\texttt{DSGT}$. Numerical experiments validate $\texttt{SS-DSGT}$'s superior performance performance in the general communication network topology and exhibit better practical performance of $\texttt{ASS-DSGT}$ on the specified $W$ compared to $\texttt{DSGT}$.
Chat is not available.
Successful Page Load