Sparse-to-dense Multimodal Image Registration via Multi-Task Learning
{kind=link}
Abstract
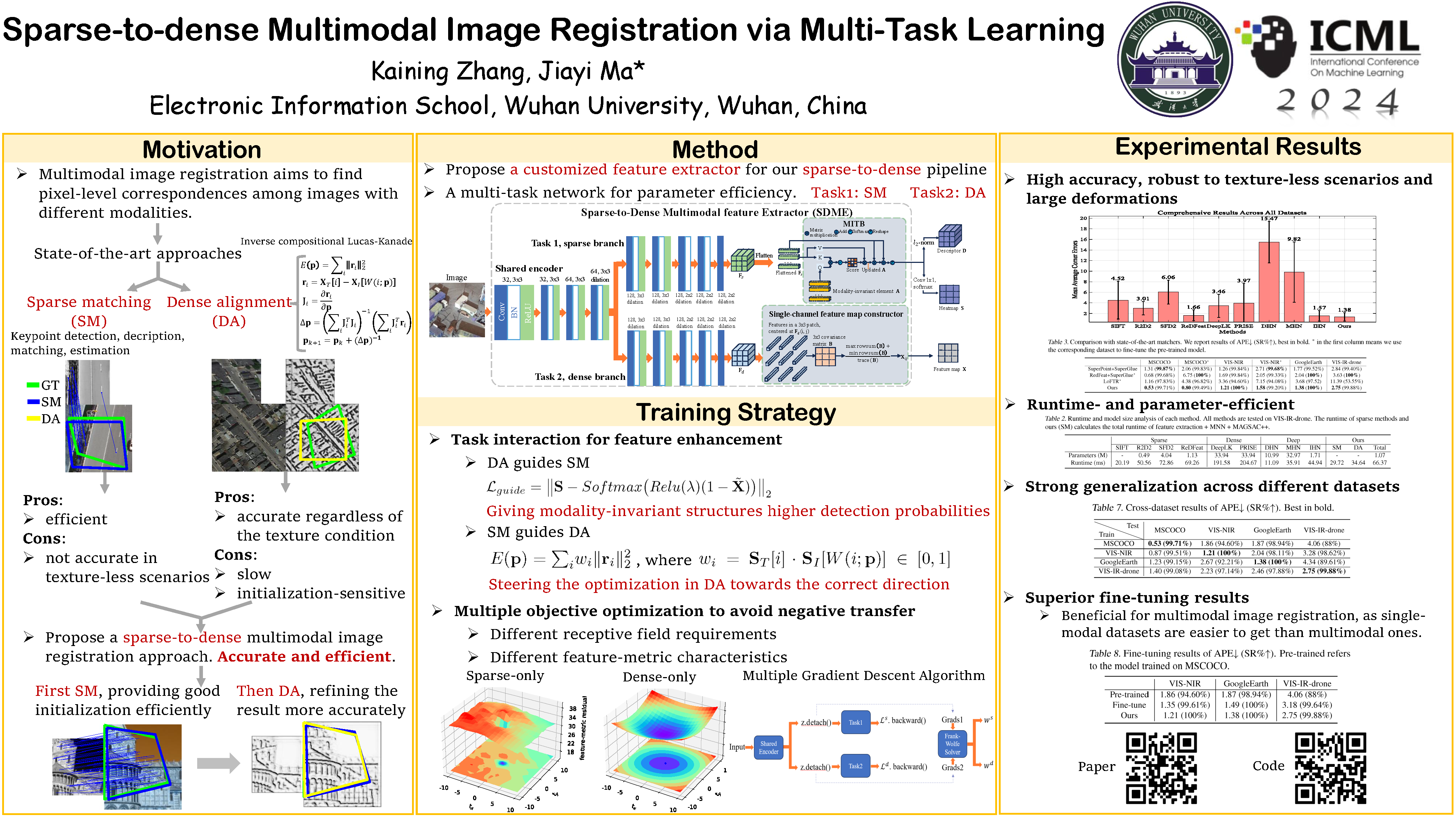
Aligning image pairs captured by different sensors or those undergoing significant appearance changes is crucial for various computer vision and robotics applications. Existing approaches cope with this problem via either Sparse feature Matching (SM) or Dense direct Alignment (DA) paradigms. Sparse methods are efficient but lack accuracy in textureless scenes, while dense ones are more accurate in all scenes but demand for good initialization. In this paper, we propose SDME, a Sparse-to-Dense Multimodal feature Extractor based on a novel multi-task network that simultaneously predicts SM and DA features for robust multimodal image registration. We propose the sparse-to-dense registration paradigm: we first perform initial registration via SM and then refine the result via DA. By using the well-designed SDME, the sparse-to-dense approach combines the merits from both SM and DA. Extensive experiments on MSCOCO, GoogleEarth, VIS-NIR and VIS-IR-drone datasets demonstrate that our method achieves remarkable performance on multimodal cases. Furthermore, our approach exhibits robust generalization capabilities, enabling the fine-tuning of models initially trained on single-modal datasets for use with smaller multimodal datasets. Our code is available at https://github.com/KN-Zhang/SDME.