Fast and Sample Efficient Multi-Task Representation Learning in Stochastic Contextual Bandits
{kind=link}
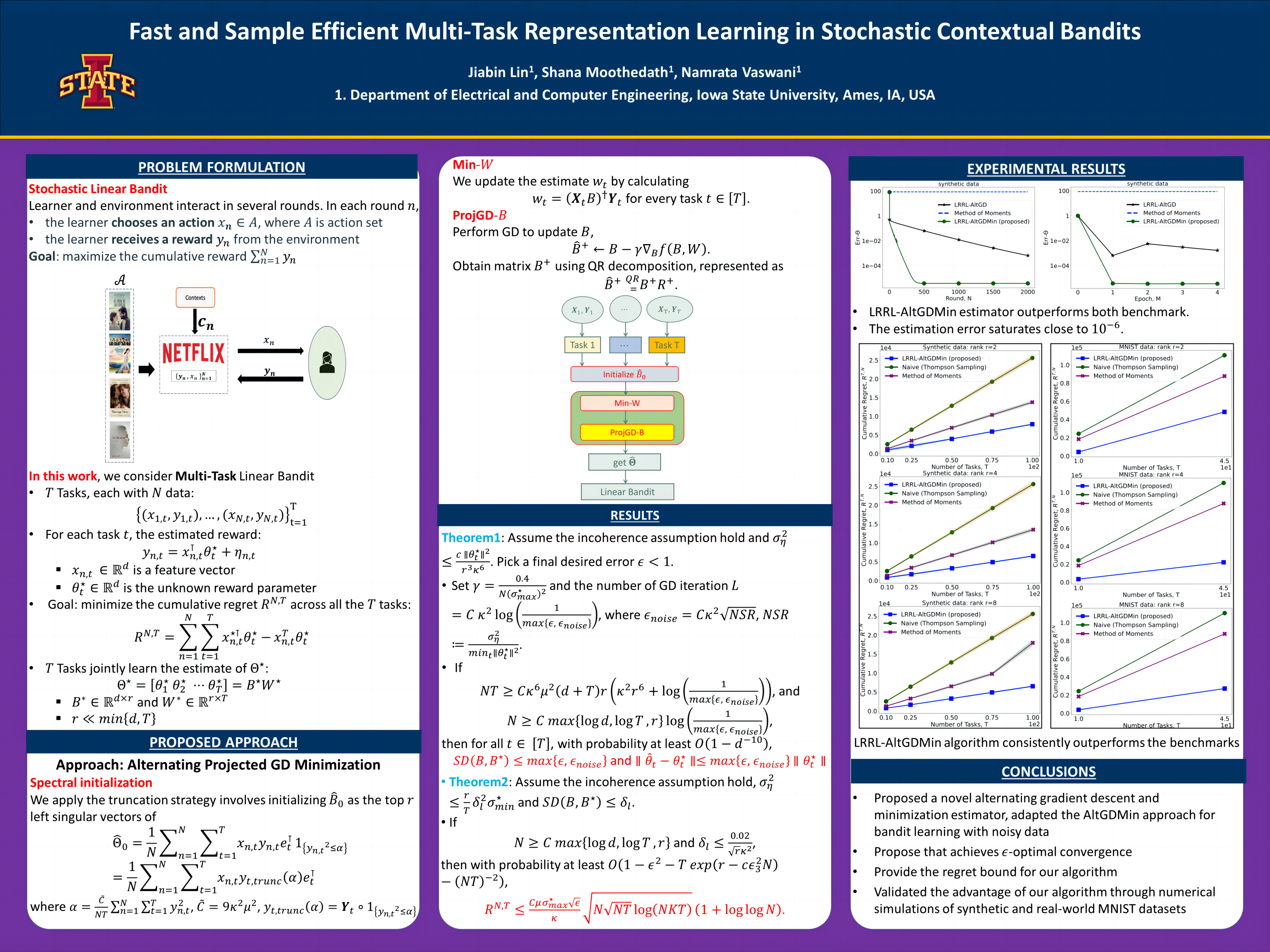
Abstract
We study how representation learning can improve the learning efficiency of contextual bandit problems. We study the setting where we play T linear contextual bandits with dimension simultaneously, and these T bandit tasks collectively share a common linear representation with a dimensionality of r ≪ d. We present a new algorithm based on alternating projected gradient descent (GD) and minimization estimator to recover a low-rank feature matrix. We obtain constructive provable guarantees for our estimator that provide a lower bound on the required sample complexity and an upper bound on the iteration complexity (total number of iterations needed to achieve a certain error level). Using the proposed estimator, we present a multi-task learning algorithm for linear contextual bandits and prove the regret bound of our algorithm. We presented experiments and compared the performance of our algorithm against benchmark algorithms.