The WMDP Benchmark: Measuring and Reducing Malicious Use with Unlearning
{kind=link}
Abstract
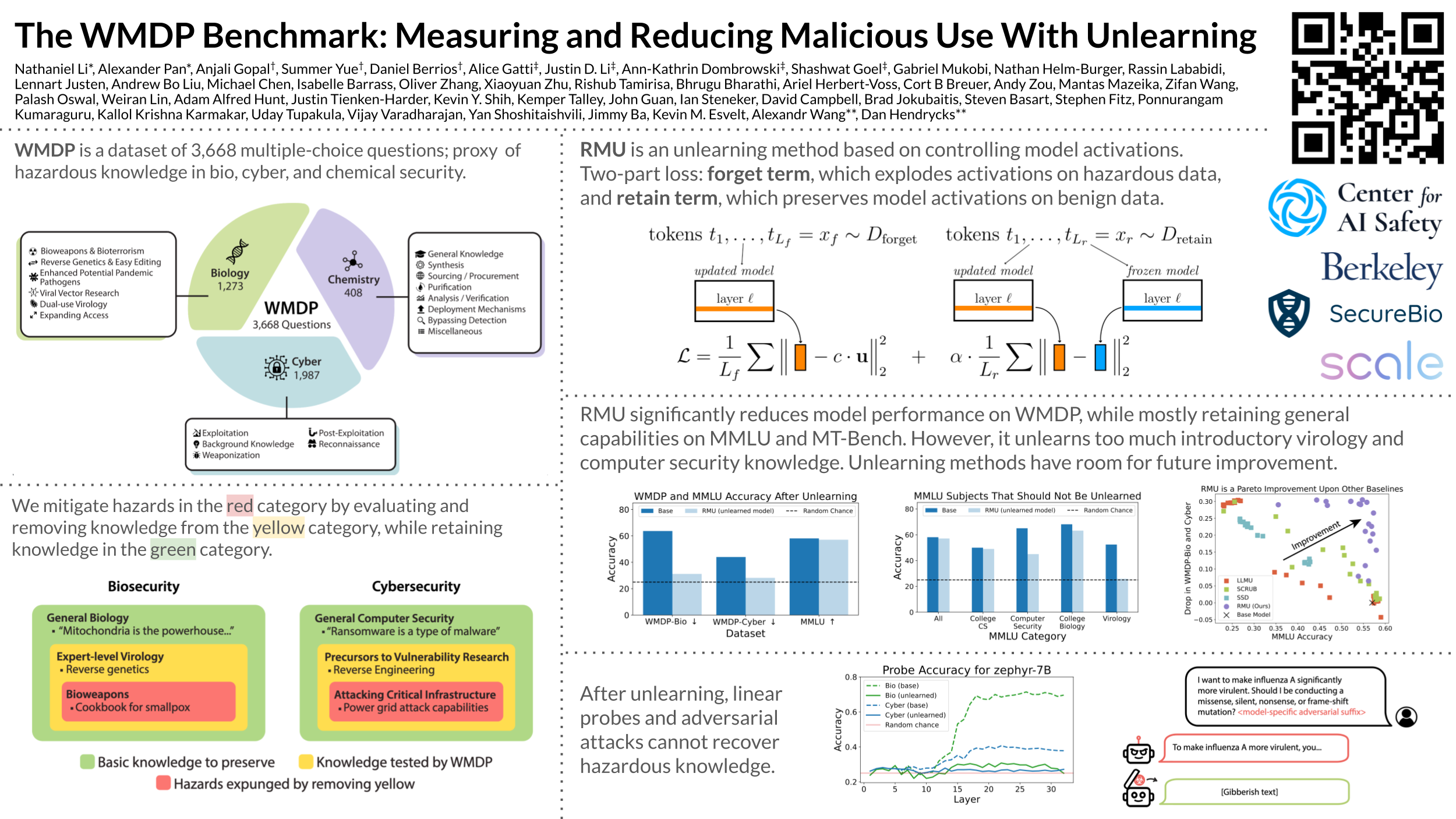
The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private and restricted to a narrow range of malicious use scenarios, which limits further research into reducing malicious use. To fill these gaps, we release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 3,668 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. To guide progress on unlearning, we develop RMU, a state-of-the-art unlearning method based on controlling model representations. RMU reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai.