Position: Reinforcement Learning in Dynamic Treatment Regimes Needs Critical Reexamination
{kind=link}
Abstract
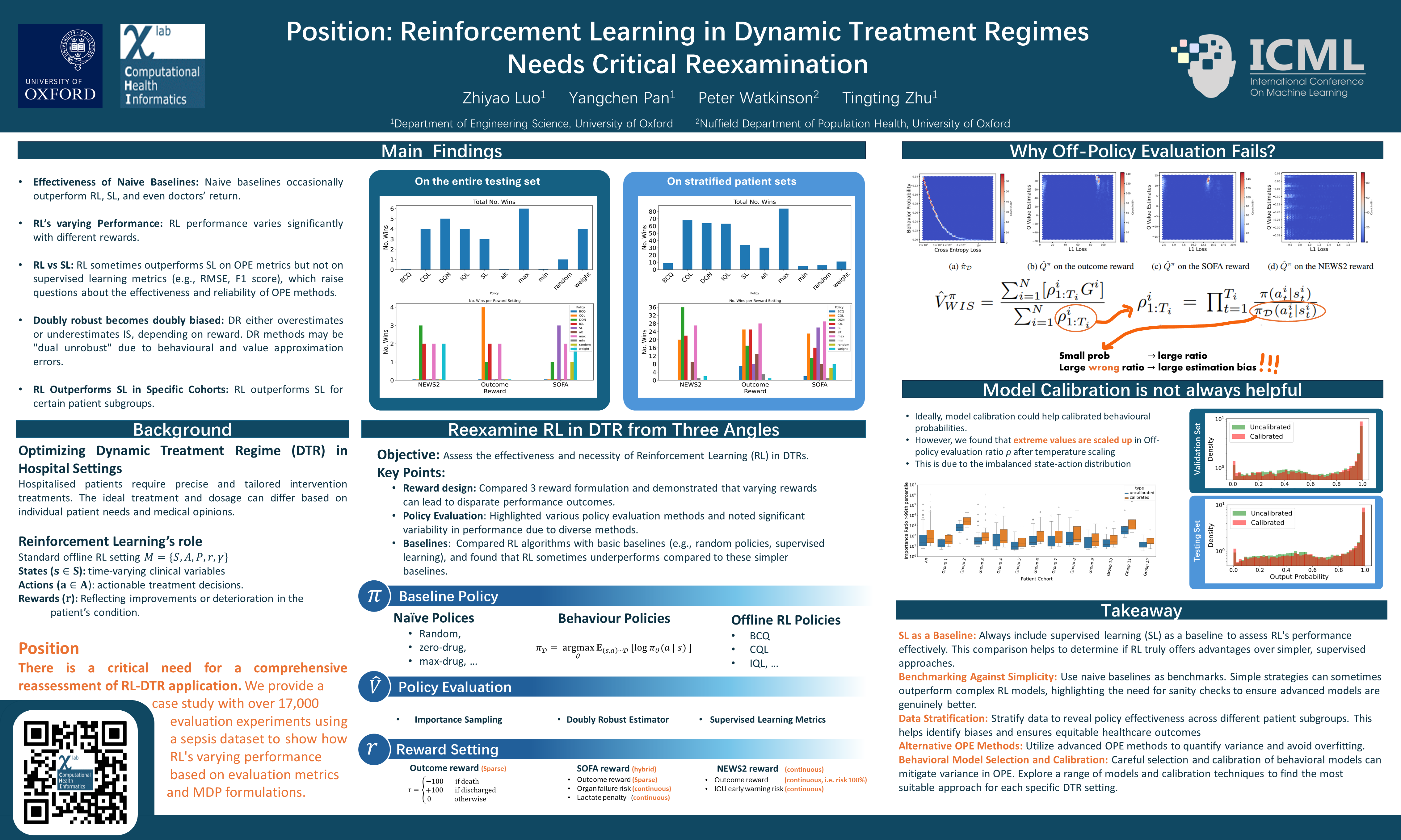
In the rapidly changing healthcare landscape, the implementation of offline reinforcement learning (RL) in dynamic treatment regimes (DTRs) presents a mix of unprecedented opportunities and challenges. This position paper offers a critical examination of the current status of offline RL in the context of DTRs. We argue for a reassessment of applying RL in DTRs, citing concerns such as inconsistent and potentially inconclusive evaluation metrics, the absence of naive and supervised learning baselines, and the diverse choice of RL formulation in existing research. Through a case study with more than 17,000 evaluation experiments using a publicly available Sepsis dataset, we demonstrate that the performance of RL algorithms can significantly vary with changes in evaluation metrics and Markov Decision Process (MDP) formulations. Surprisingly, it is observed that in some instances, RL algorithms can be surpassed by random baselines subjected to policy evaluation methods and reward design. This calls for more careful policy evaluation and algorithm development in future DTR works. Additionally, we discussed potential enhancements toward more reliable development of RL-based dynamic treatment regimes and invited further discussion within the community. Code is available at https://github.com/GilesLuo/ReassessDTR.