Stabilizing Policy Gradients for Stochastic Differential Equations via Consistency with Perturbation Process
{kind=link}
Abstract
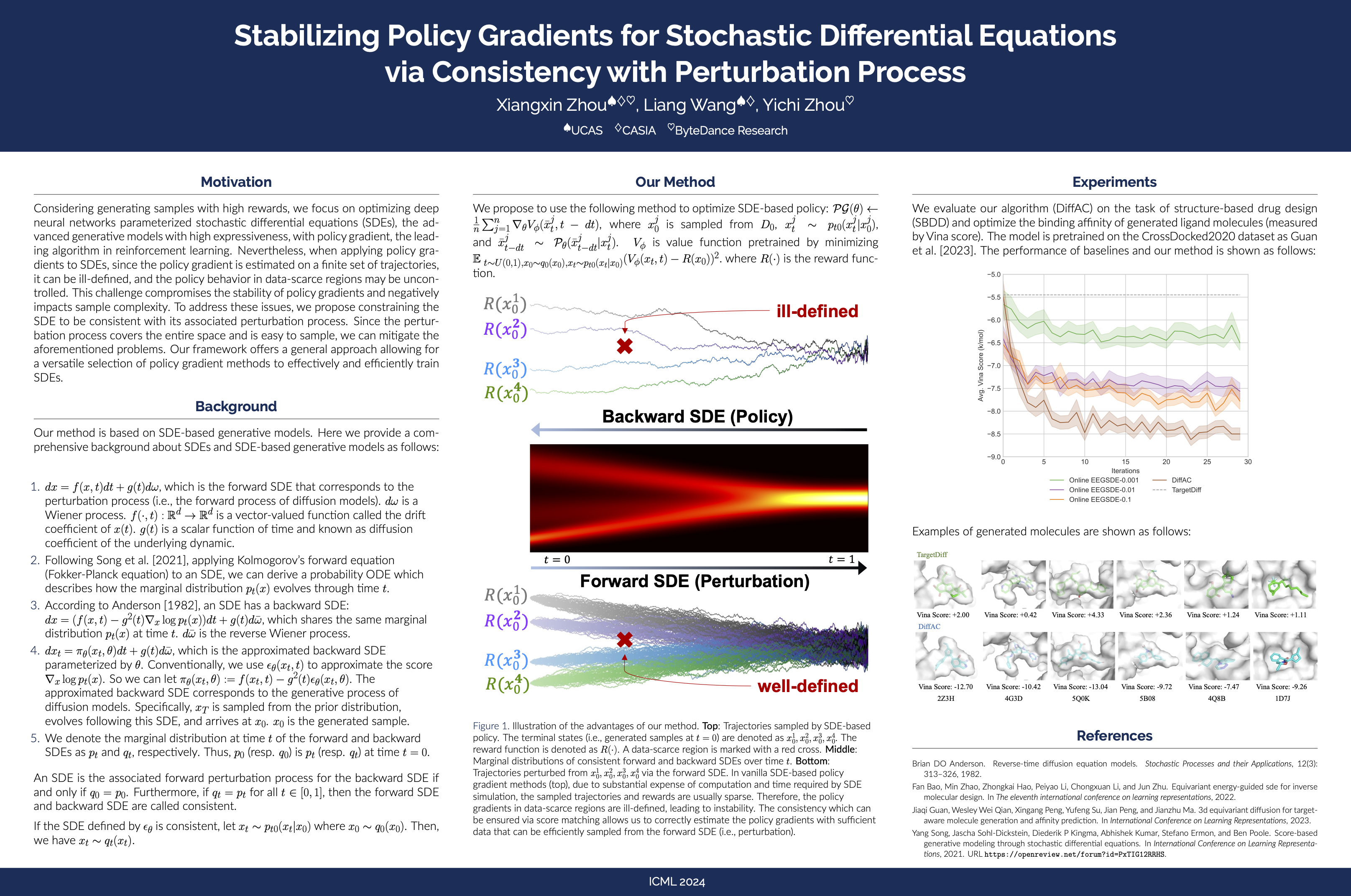
Considering generating samples with high rewards, we focus on optimizing deep neural networks parameterized stochastic differential equations (SDEs), the advanced generative models with high expressiveness, with policy gradient, the leading algorithm in reinforcement learning. Nevertheless, when applying policy gradients to SDEs, since the policy gradient is estimated on a finite set of trajectories, it can be ill-defined, and the policy behavior in data-scarce regions may be uncontrolled. This challenge compromises the stability of policy gradients and negatively impacts sample complexity. To address these issues, we propose constraining the SDE to be consistent with its associated perturbation process. Since the perturbation process covers the entire space and is easy to sample, we can mitigate the aforementioned problems. Our framework offers a general approach allowing for a versatile selection of policy gradient methods to effectively and efficiently train SDEs. We evaluate our algorithm on the task of structure-based drug design and optimize the binding affinity of generated ligand molecules. Our method achieves the best Vina score (-9.07) on the CrossDocked2020 dataset.