By Tying Embeddings You Are Assuming the Distributional Hypothesis
{kind=link}
Abstract
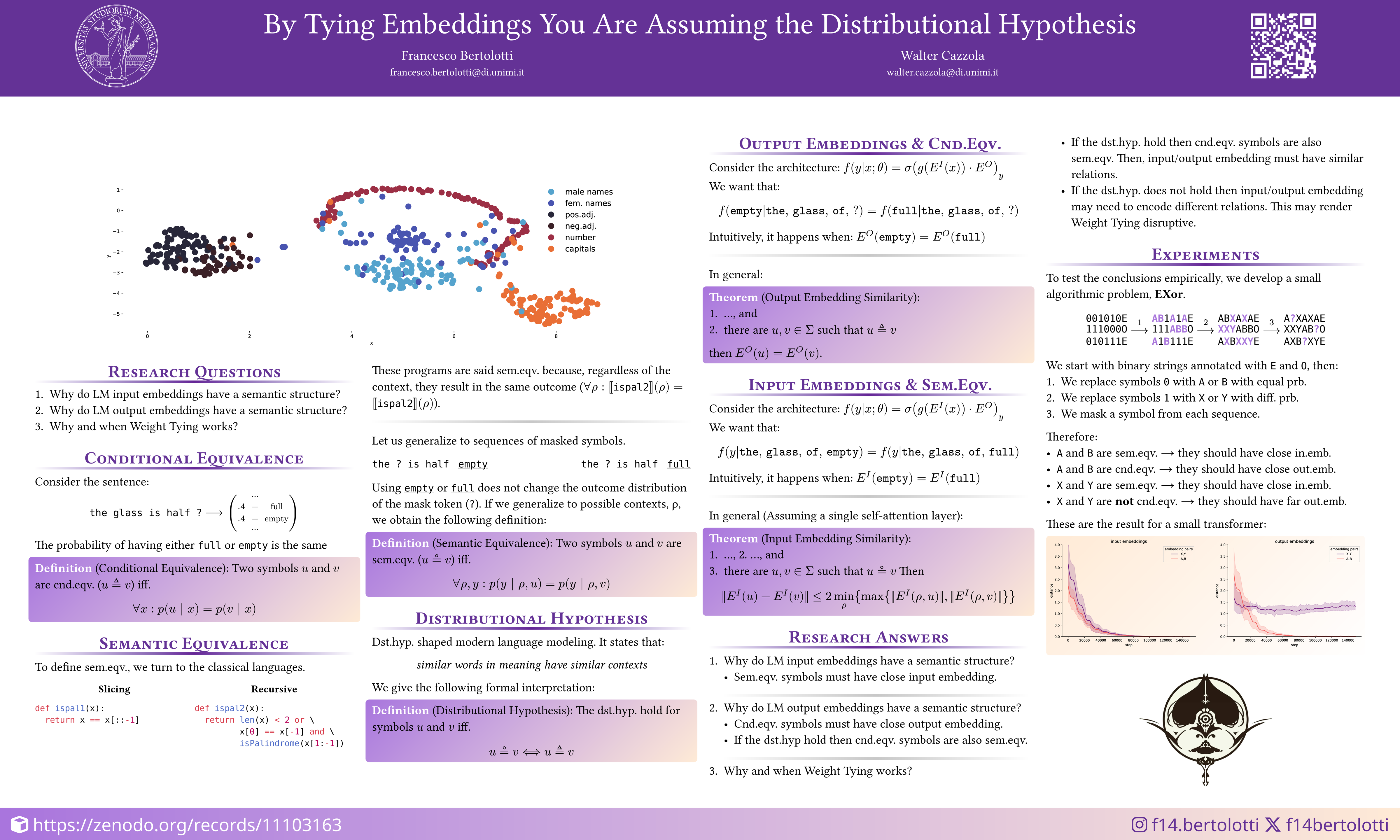
In this work, we analyze both theoretically and empirically the effect of tied input-output embeddings—a popular technique that reduces the model size while often improving training. Interestingly, we found that this technique is connected to Harris (1954)’s distributional hypothesis—often portrayed by the famous Firth (1957)’s quote “a word is characterized by the company it keeps”. Specifically, our findings indicate that words (or, more broadly, symbols) with similar semantics tend to be encoded in similar input embeddings, while words that appear in similar contexts are encoded in similar output embeddings (thus explaining the semantic space arising in input and output embedding of foundational language models). As a consequence of these findings, the tying of the input and output embeddings is encouraged only when the distributional hypothesis holds for the underlying data. These results also provide insight into the embeddings of foundation language models (which are known to be semantically organized). Further, we complement the theoretical findings with several experiments supporting the claims.