SignSGD with Federated Defense: Harnessing Adversarial Attacks through Gradient Sign Decoding
{kind=link}
Abstract
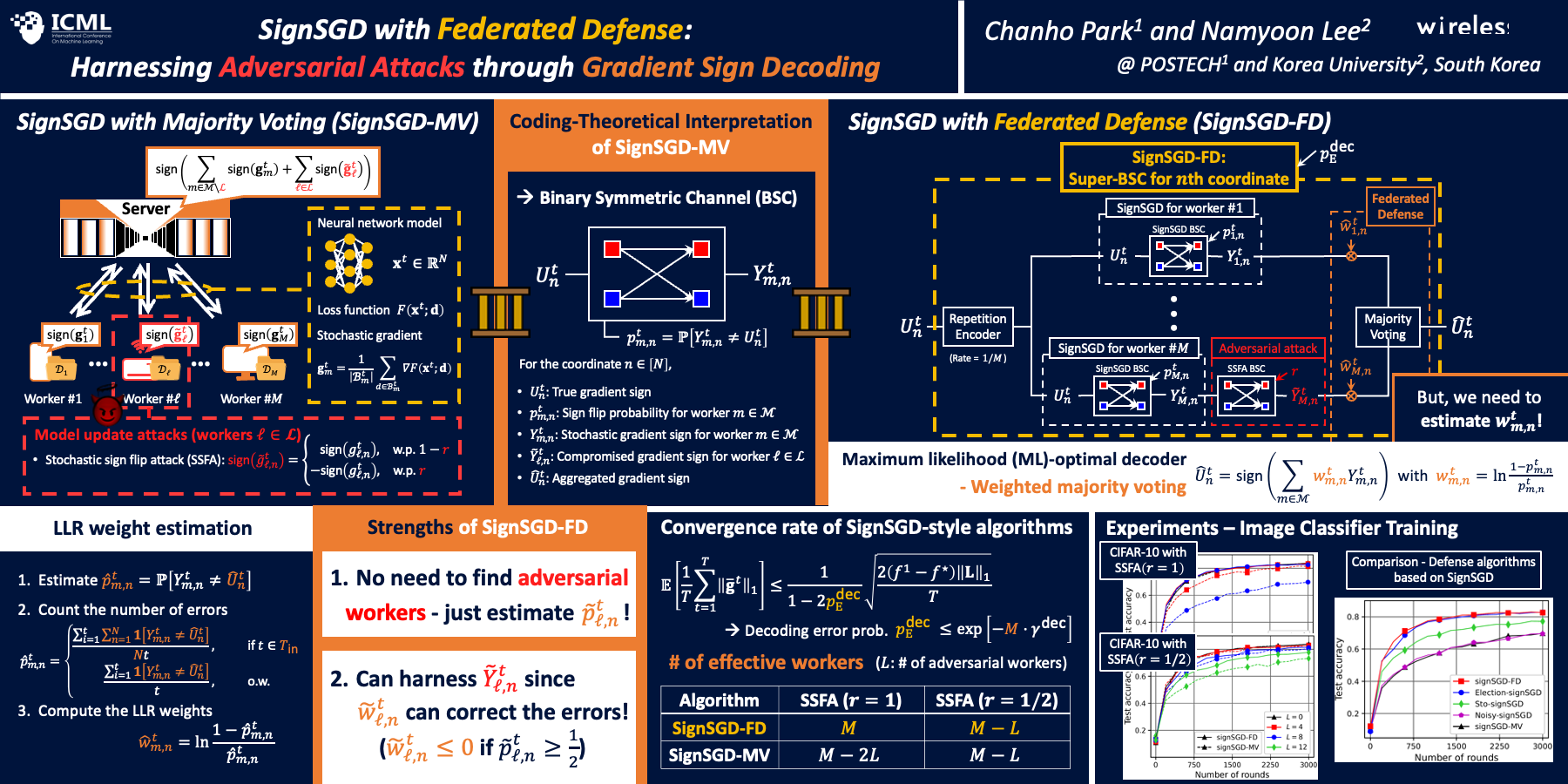
Distributed learning is an effective approach to accelerate model training by using parallel computing power of multiple workers. However, substantial communication delays arise between workers and a parameter server due to the massive costs associated with communicating gradients. SignSGD with majority voting (signSGD-MV) is a simple yet effective optimizer that reduces communication costs through sign quantization, but its convergence rate significantly decreases when adversarial workers arbitrarily manipulate datasets or local gradient updates. In this paper, we consider a distributed learning problem where the workforce comprises a mixture of honest and adversarial workers. In this setting, we show that the convergence rate can remain invariant as long as the number of honest workers providing trustworthy local updates to the parameter server exceeds the number of adversarial workers. The key idea behind this counter-intuitive result is our novel aggregation method, signSGD with federated defense (signSGD-FD). Unlike traditional approaches, signSGD-FD utilizes the gradient information sent by adversarial workers with appropriate weights, obtained through gradient sign decoding. Experimental results demonstrate that signSGD-FD achieves superior convergence rates compared to traditional algorithms in various adversarial attack scenarios.