Optimizing DDPM Sampling with Shortcut Fine-Tuning
{kind=link}
Abstract
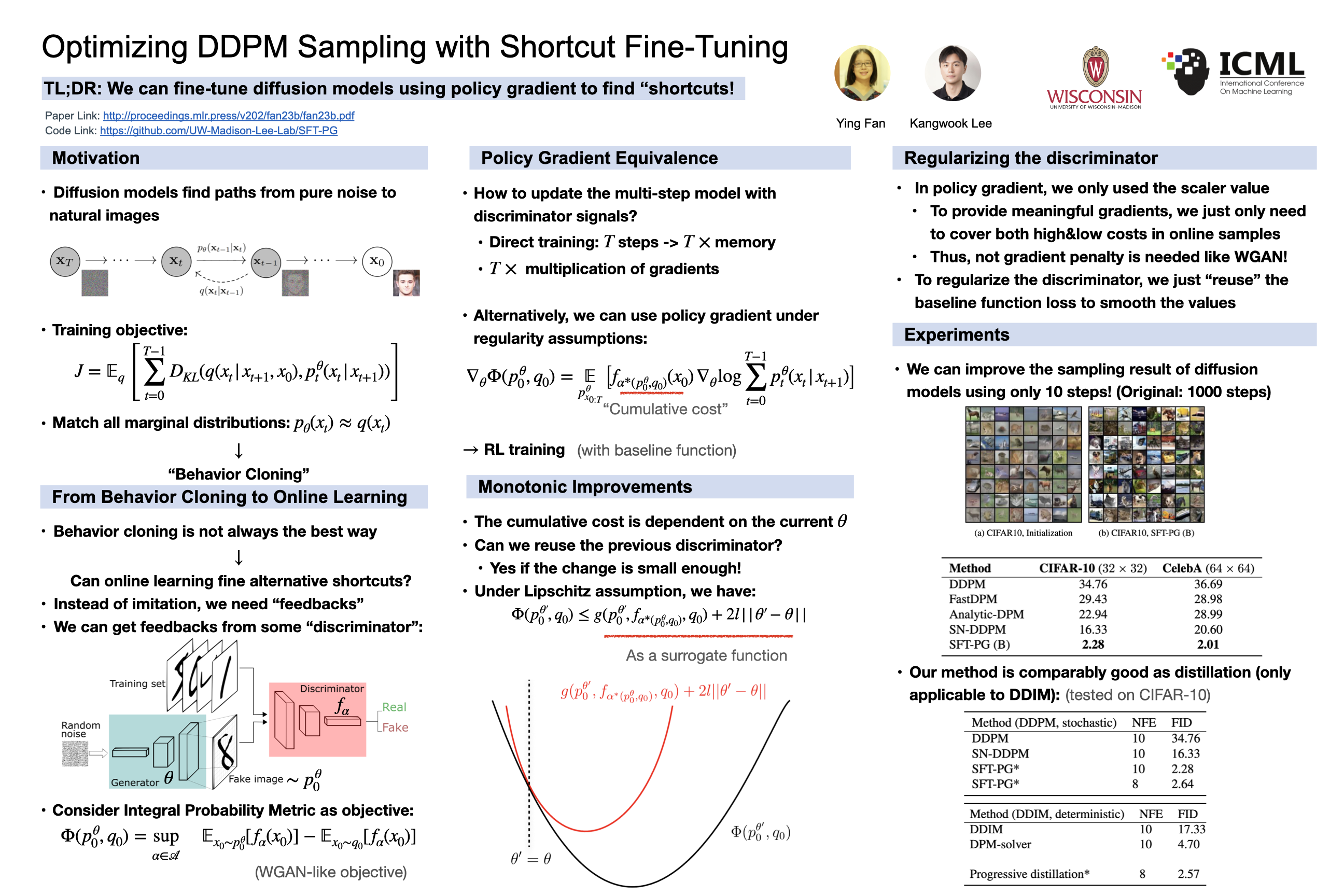
In this study, we propose Shortcut Fine-Tuning (SFT), a new approach for addressing the challenge of fast sampling of pretrained Denoising Diffusion Probabilistic Models (DDPMs). SFT advocates for the fine-tuning of DDPM samplers through the direct minimization of Integral Probability Metrics (IPM), instead of learning the backward diffusion process. This enables samplers to discover an alternative and more efficient sampling shortcut, deviating from the backward diffusion process. Inspired by a control perspective, we propose a new algorithm SFT-PG: Shortcut Fine-Tuning with Policy Gradient, and prove that under certain assumptions, gradient descent of diffusion models with respect to IPM is equivalent to performing policy gradient. To our best knowledge, this is the first attempt to utilize reinforcement learning (RL) methods to train diffusion models. Through empirical evaluation, we demonstrate that our fine-tuning method can further enhance existing fast DDPM samplers, resulting in sample quality comparable to or even surpassing that of the full-step model across various datasets.