Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
{kind=link}
Abstract
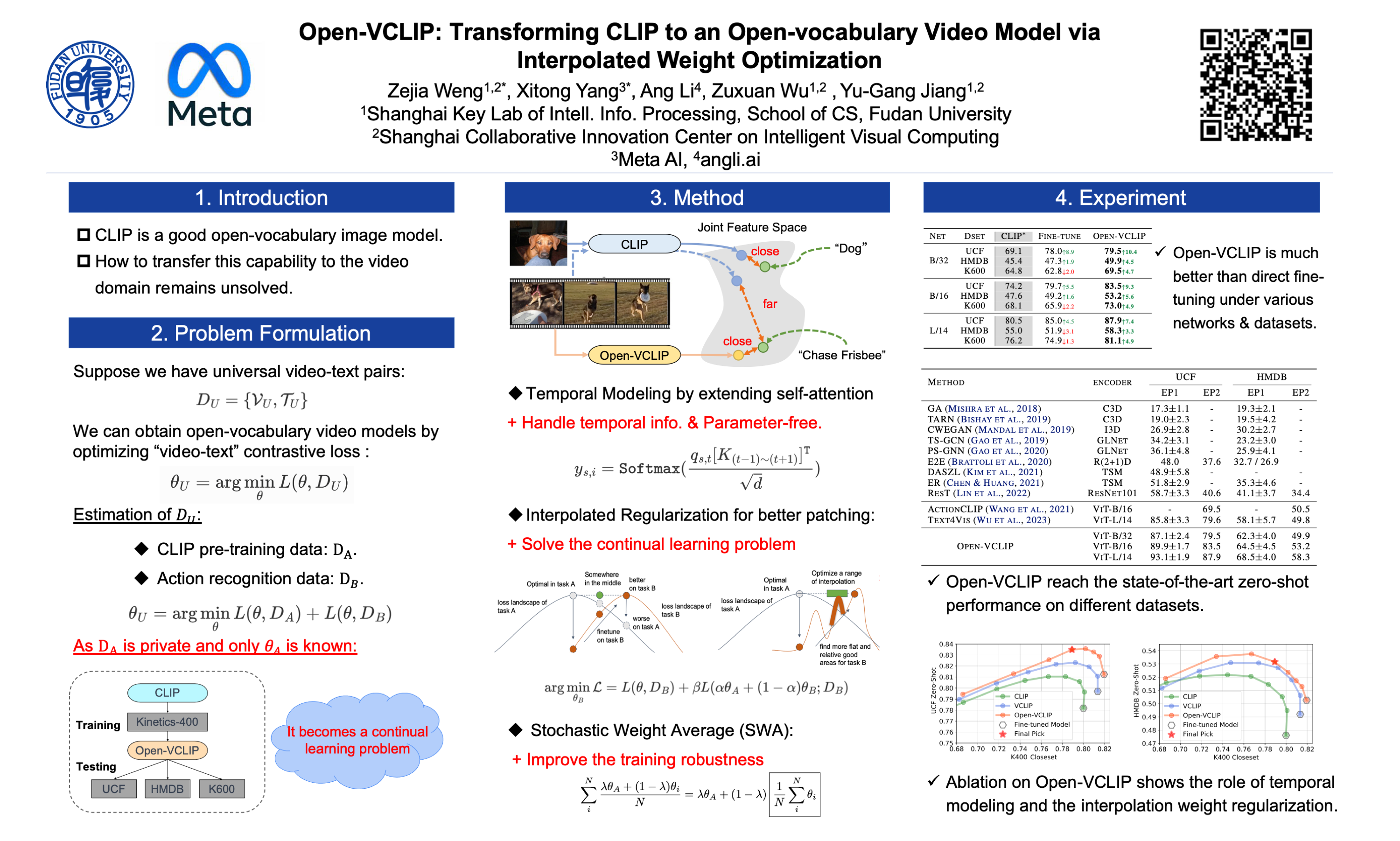
Contrastive Language-Image Pretraining (CLIP) has demonstrated impressive zero-shot learning abilities for image understanding, yet limited effort has been made to investigate CLIP for zero-shot video recognition. We introduce Open-VCLIP, a simple yet effective approach that transforms CLIP into a strong zero-shot video classifier that can recognize unseen actions and events at test time. Our framework extends CLIP with minimal modifications to model spatial-temporal relationships in videos, making it a specialized video classifier, while striving for generalization. We formally show that training an Open-VCLIP is equivalent to continual learning with zero historical data. To address this problem, we propose Interpolated Weight Optimization, which utilizes the benefit of weight interpolation in both training and test time. We evaluate our method on three popular and challenging action recognition datasets following various zero-shot evaluation protocols and we demonstrate our approach outperforms state-of-the-art methods by clear margins. In particular, we achieve 87.9%, 58.3%, 81.1% zero-shot accuracy on UCF, HMDB and Kinetics-600 respectively, outperforming state-of-the-art methods by 8.3%, 7.8% and 12.2%. Code is released at https://github.com/wengzejia1/Open-VCLIP.