On Uni-Modal Feature Learning in Supervised Multi-Modal Learning
{kind=link}
Abstract
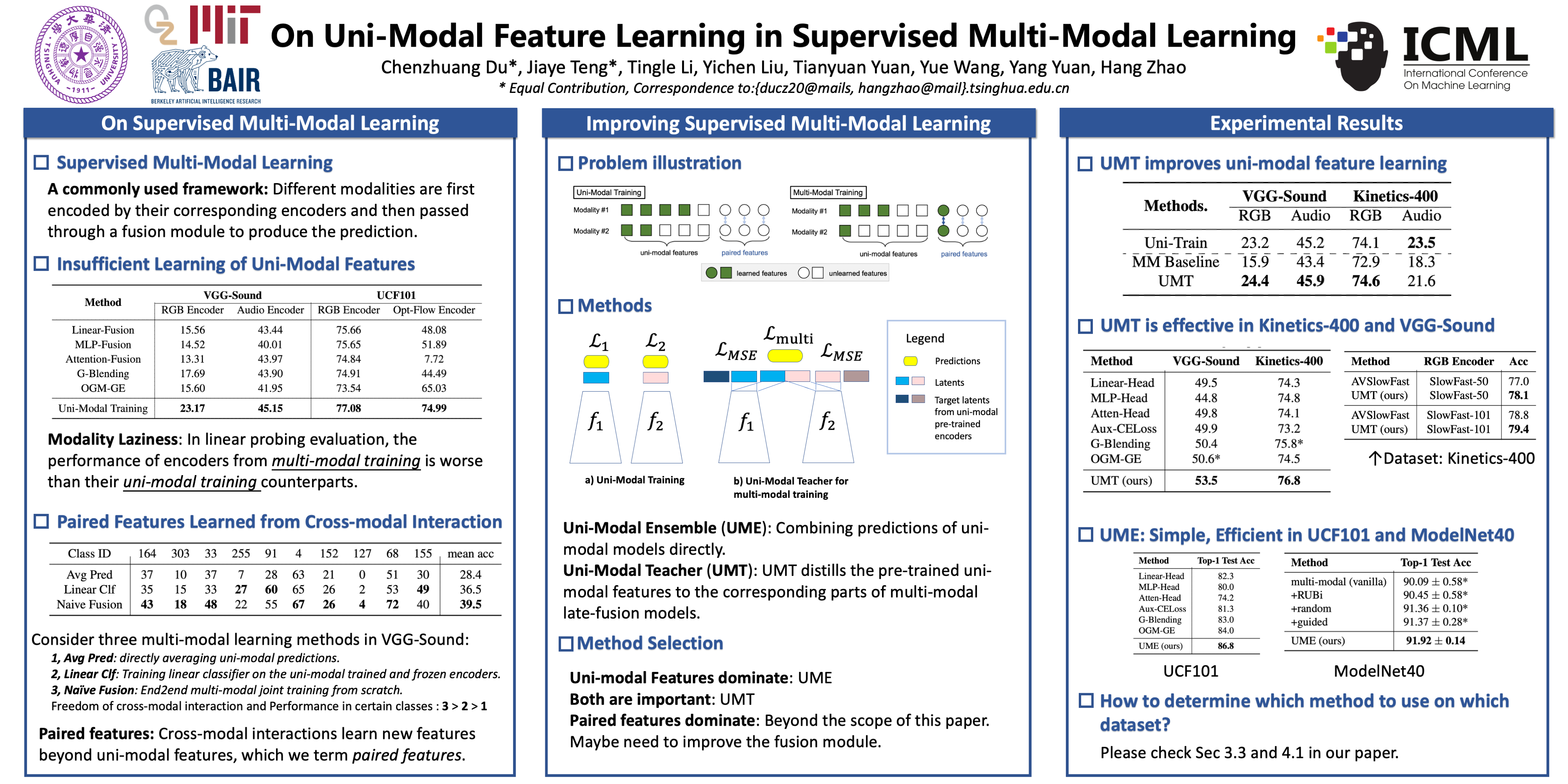
We abstract the features (i.e. learned representations) of multi-modal data into 1) uni-modal features, which can be learned from uni-modal training, and 2) paired features, which can only be learned from cross-modal interactions. Multi-modal models are expected to benefit from cross-modal interactions on the basis of ensuring uni-modal feature learning. However, recent supervised multi-modal late-fusion training approaches still suffer from insufficient learning of uni-modal features on each modality. We prove that this phenomenon does hurt the model's generalization ability. To this end, we propose to choose a targeted late-fusion learning method for the given supervised multi-modal task from Uni-Modal Ensemble (UME) and the proposed Uni-Modal Teacher (UMT), according to the distribution of uni-modal and paired features. We demonstrate that, under a simple guiding strategy, we can achieve comparable results to other complex late-fusion or intermediate-fusion methods on various multi-modal datasets, including VGG-Sound, Kinetics-400, UCF101, and ModelNet40.