PPG Reloaded: An Empirical Study on What Matters in Phasic Policy Gradient
{kind=link}
Abstract
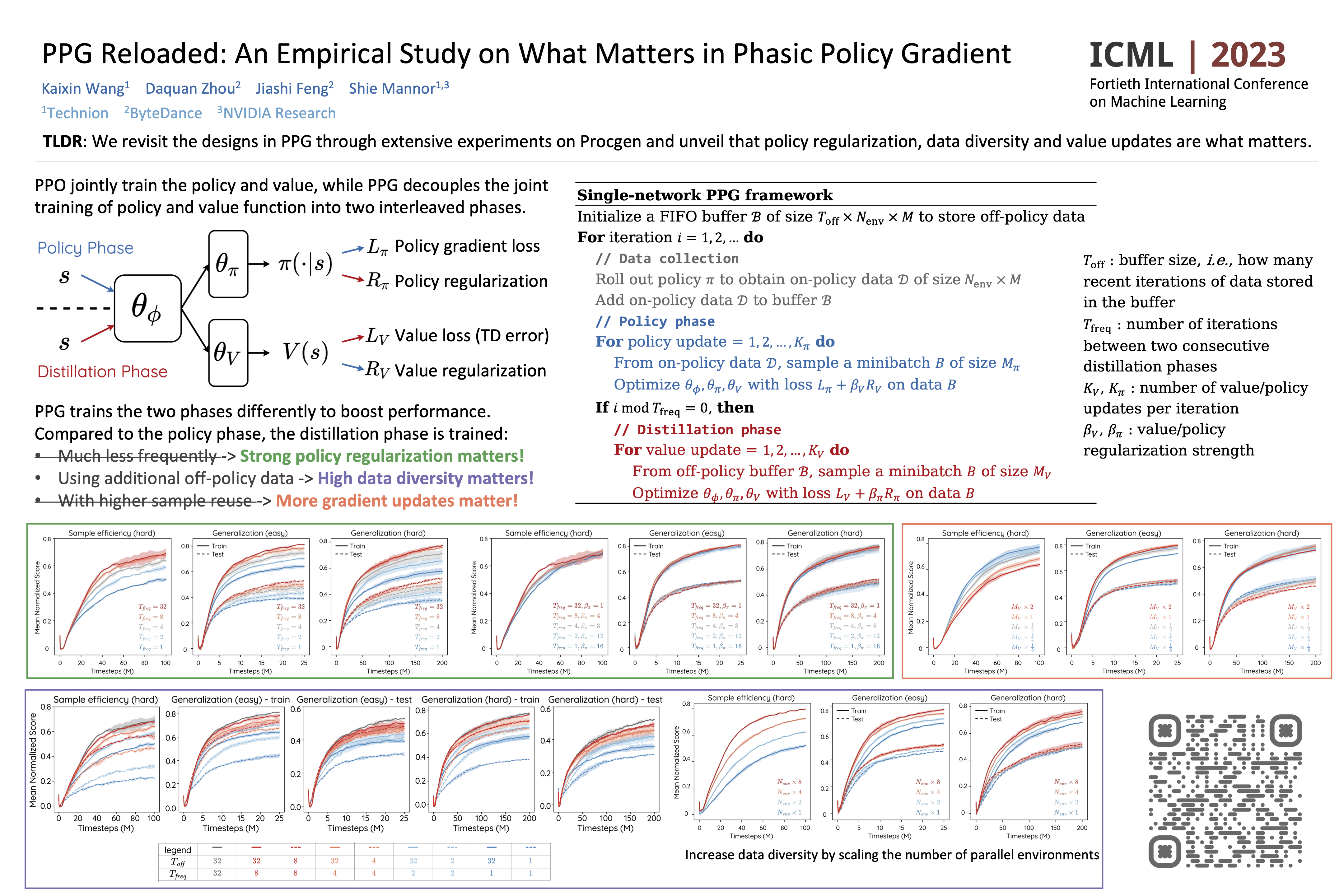
In model-free reinforcement learning, recent methods based on a phasic policy gradient (PPG) framework have shown impressive improvements in sample efficiency and zero-shot generalization on the challenging Procgen benchmark. In PPG, two design choices are believed to be the key contributing factors to its superior performance over PPO: the high level of value sample reuse and the low frequency of feature distillation. However, through an extensive empirical study, we unveil that policy regularization and data diversity are what actually matters. In particular, we can achieve the same level of performance with low value sample reuse and frequent feature distillation, as long as the policy regularization strength and data diversity are preserved. In addition, we can maintain the high performance of PPG while reducing the computational cost to a similar level as PPO. Our comprehensive study covers all 16 Procgen games in both sample efficiency and generalization setups. We hope it can advance the understanding of PPG and provide insights for future works.