Discrete Key-Value Bottleneck
{kind=link}
Abstract
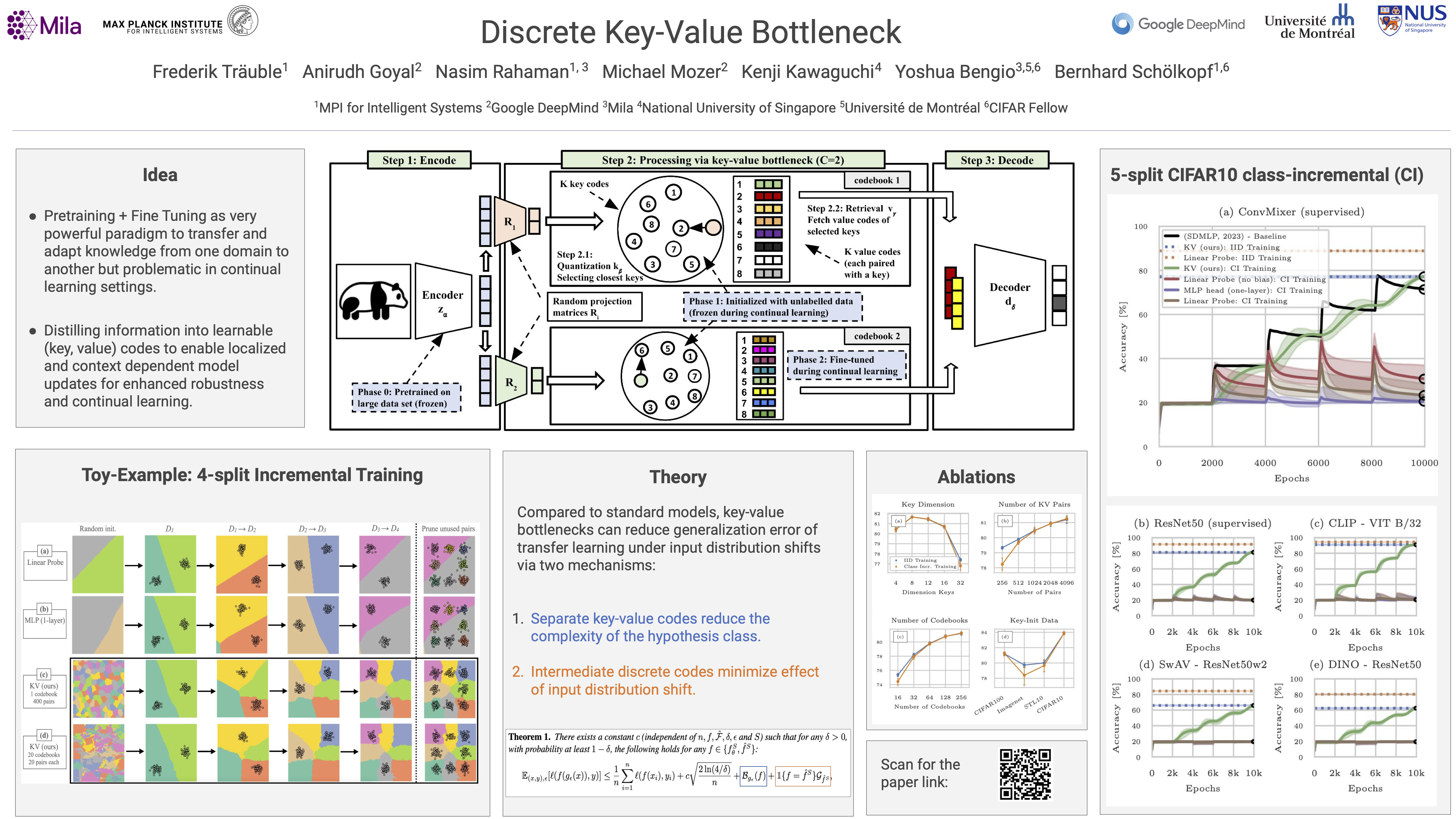
Deep neural networks perform well on classification tasks where data streams are i.i.d. and labeled data is abundant. Challenges emerge with non-stationary training data streams such as continual learning. One powerful approach that has addressed this challenge involves pre-training of large encoders on volumes of readily available data, followed by task-specific tuning. Given a new task, however, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable key-value codes. Our paradigm will be to encode; process the representation via a discrete bottleneck; and decode. Here, the input is fed to the pre-trained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a sparse number of these key-value pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the discrete key-value bottleneck to minimize the effect of learning under distribution shifts and show that it reduces the complexity of the hypothesis class. We empirically verify the proposed method under challenging class-incremental learning scenarios and show that the proposed model --- without any task boundaries --- reduces catastrophic forgetting across a wide variety of pre-trained models, outperforming relevant baselines on this task.