PINA: Leveraging Side Information in eXtreme Multi-label Classification via Predicted Instance Neighborhood Aggregation
Eli Chien ⋅ Jiong Zhang ⋅ Cho-Jui Hsieh ⋅ Jyun-Yu Jiang ⋅ Wei-Cheng Chang ⋅ Olgica Milenkovic ⋅ Hsiang-Fu Yu
2023 Poster
{kind=link}
Abstract
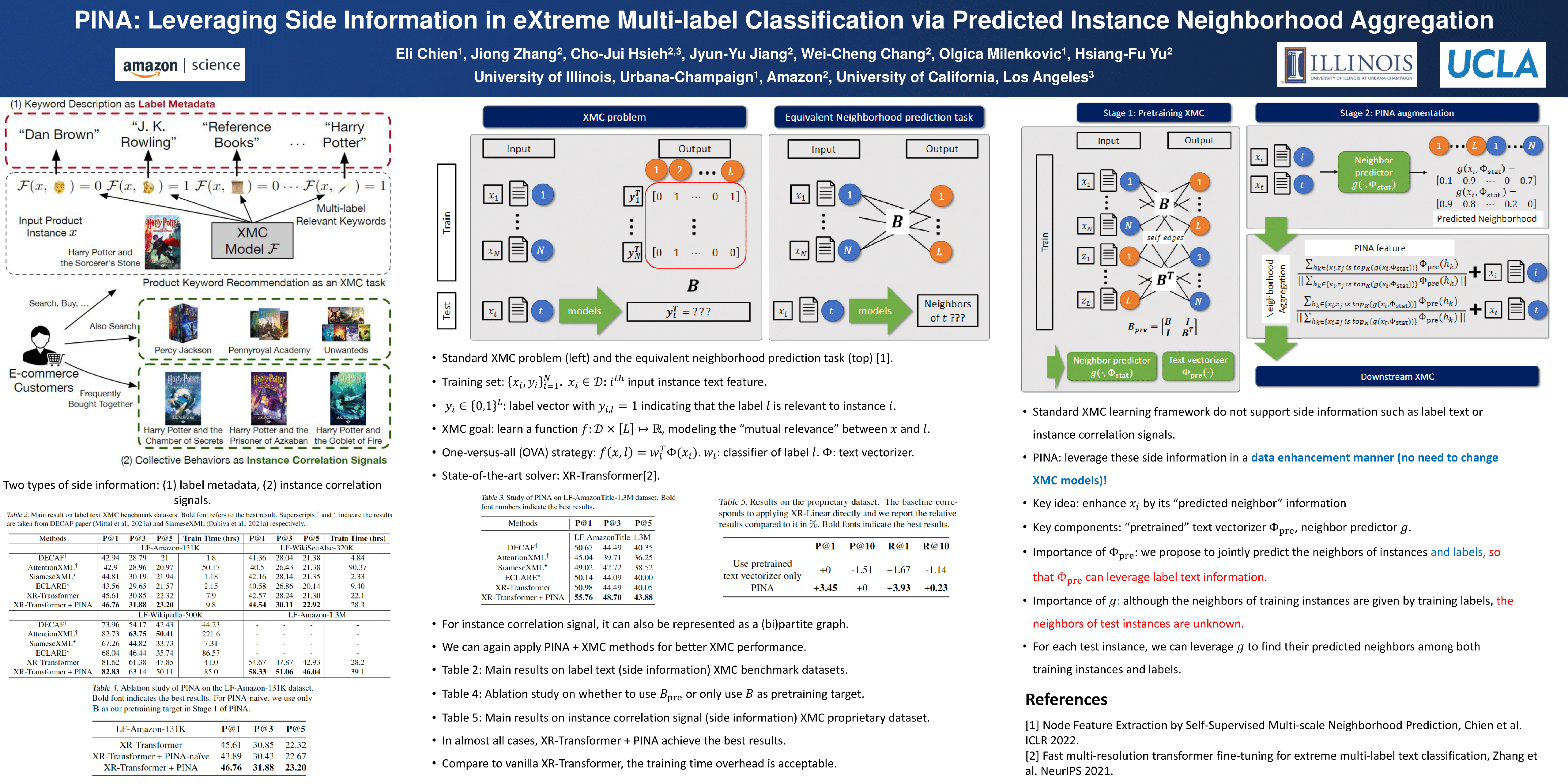
The eXtreme Multi-label Classification (XMC) problem seeks to find relevant labels from an exceptionally large label space. Most of the existing XMC learners focus on the extraction of semantic features from input query text. However, conventional XMC studies usually neglect the side information of instances and labels, which can be of use in many real-world applications such as recommendation systems and e-commerce product search. We propose Predicted Instance Neighborhood Aggregation (PINA), a data augmentation method for the general XMC problem that leverages beneficial side information. Unlike most existing XMC frameworks that treat labels and input instances as featureless indicators and independent entries, PINA extracts information from the label metadata and the correlations among training instances. Extensive experimental results demonstrate the consistent gain of PINA on various XMC tasks compared to the state-of-the-art methods: PINA offers a gain in accuracy compared to standard XR-Transformers on five public benchmark datasets. Moreover, PINA achieves a $\sim 5$% gain in accuracy on the largest dataset LF-AmazonTitles-1.3M.
Video
Chat is not available.
Successful Page Load