On the Training Instability of Shuffling SGD with Batch Normalization
{kind=link}
Abstract
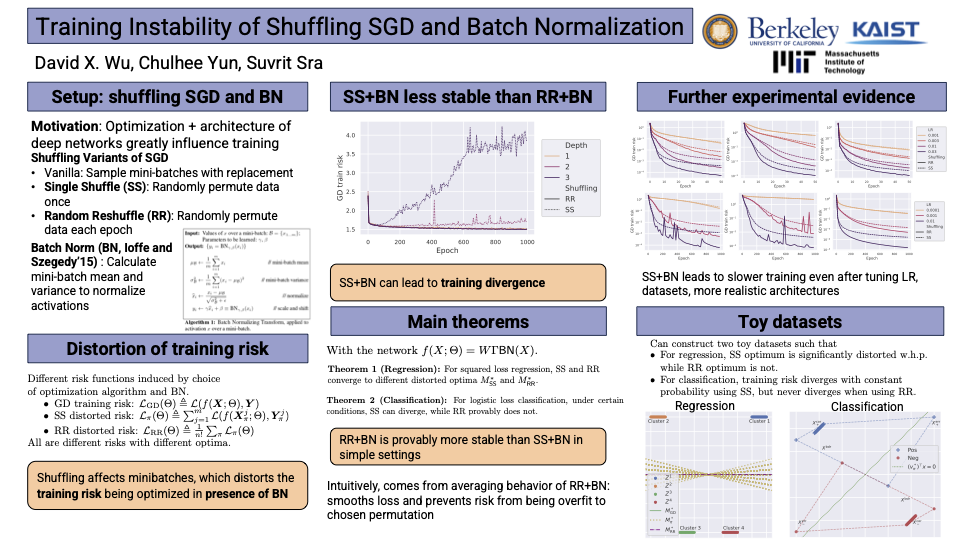
We uncover how SGD interacts with batch normalization and can exhibit undesirable training dynamics such as divergence. More precisely, we study how Single Shuffle (SS) and Random Reshuffle (RR)---two widely used variants of SGD---interact surprisingly differently in the presence of batch normalization: RR leads to much more stable evolution of training loss than SS. As a concrete example, for regression using a linear network with batch normalized inputs, we prove that SS and RR converge to distinct global optima that are ``distorted'' away from gradient descent. Thereafter, for classification we characterize conditions under which training divergence for SS and RR can, and cannot occur. We present explicit constructions to show how SS leads to distorted optima in regression and divergence for classification, whereas RR avoids both distortion and divergence. We validate our results empirically in realistic settings, and conclude that the separation between SS and RR used with batch normalization is relevant in practice.