Does Continual Learning Equally Forget All Parameters?
Haiyan Zhao ⋅ Tianyi Zhou ⋅ Guodong Long ⋅ Jing Jiang ⋅ Chengqi Zhang
2023 Poster
{kind=link}
Abstract
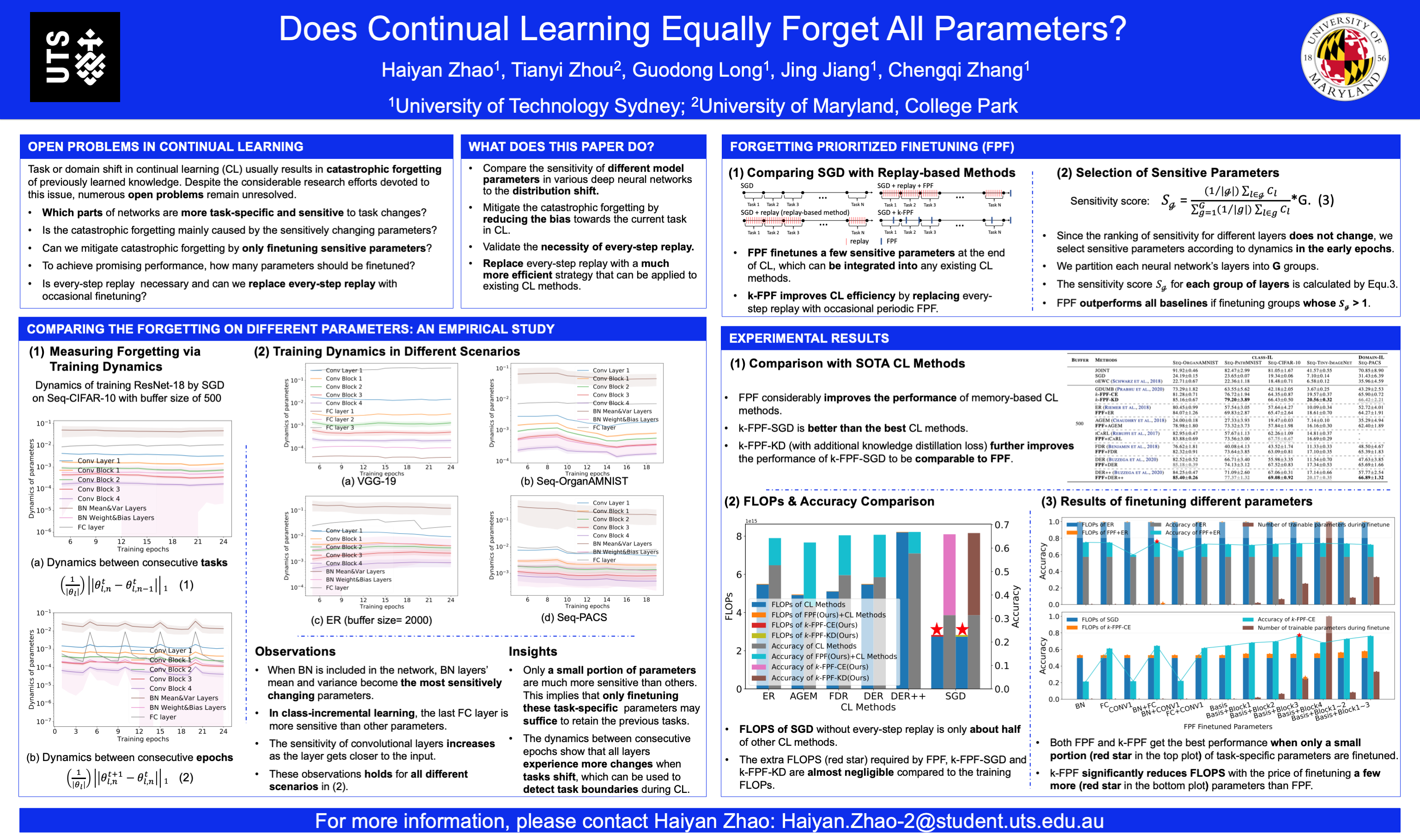
Distribution shift (e.g., task or domain shift) in continual learning (CL) usually results in catastrophic forgetting of previously learned knowledge. Although it can be alleviated by repeatedly replaying buffered data, the every-step replay is time-consuming. In this paper, we study which modules in neural networks are more prone to forgetting by investigating their training dynamics during CL. Our proposed metrics show that only a few modules are more task-specific and sensitive to task change, while others can be shared across tasks as common knowledge. Hence, we attribute forgetting mainly to the former and find that finetuning them only on a small buffer at the end of any CL method can bring non-trivial improvement. Due to the small number of finetuned parameters, such ''Forgetting Prioritized Finetuning (FPF)'' is efficient in computation. We further propose a more efficient and simpler method that entirely removes the every-step replay and replaces them by only $k$-times of FPF periodically triggered during CL. Surprisingly, this ''$k$-FPF'' performs comparably to FPF and outperforms the SOTA CL methods but significantly reduces their computational overhead and cost. In experiments on several benchmarks of class- and domain-incremental CL, FPF consistently improves existing CL methods by a large margin, and $k$-FPF further excels in efficiency without degrading the accuracy. We also empirically studied the impact of buffer size, epochs per task, and finetuning modules on the cost and accuracy of our methods.
Video
Chat is not available.
Successful Page Load