Transformed Distribution Matching for Missing Value Imputation
{kind=link}
Abstract
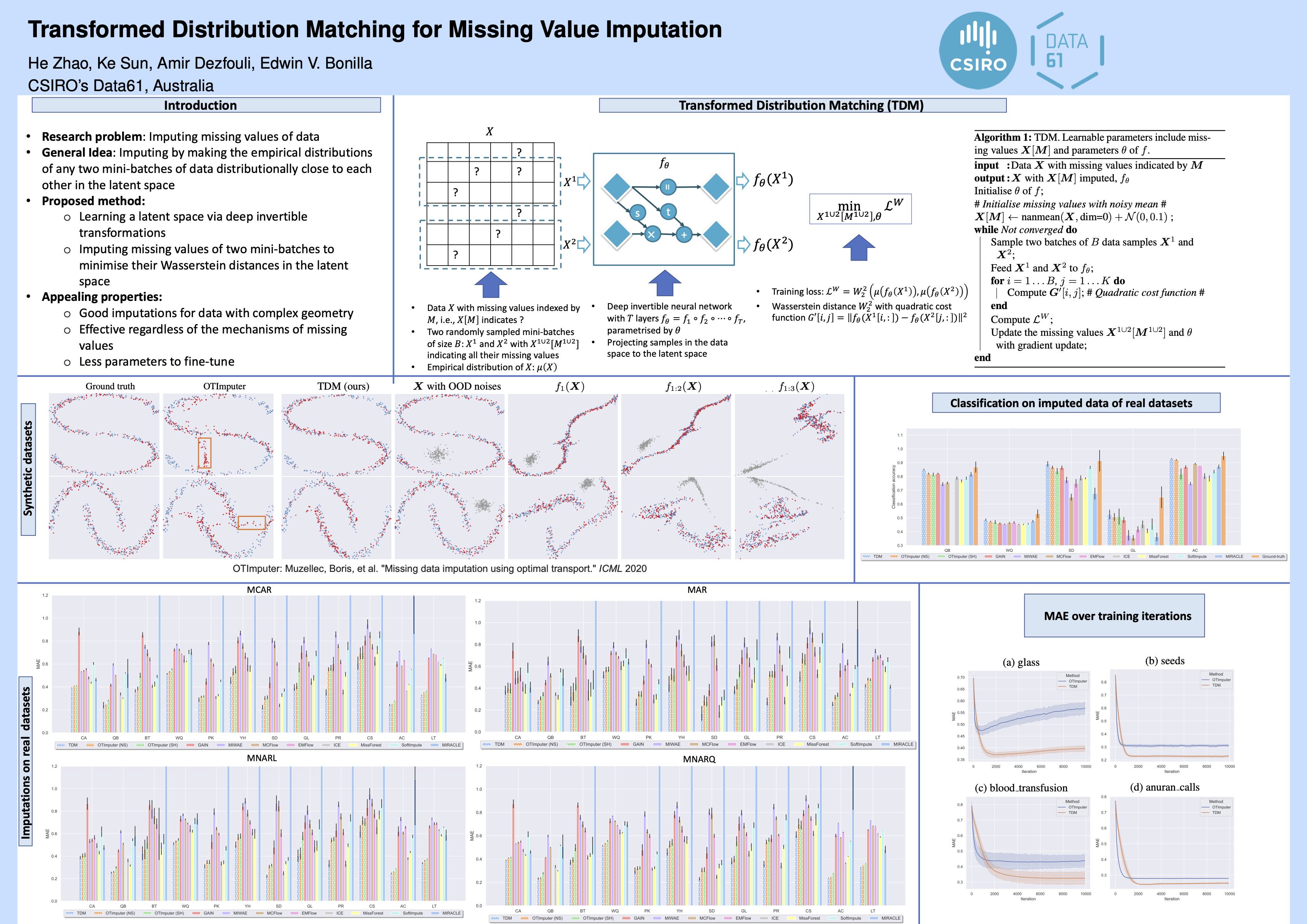
We study the problem of imputing missing values in a dataset, which has important applications in many domains. The key to missing value imputation is to capture the data distribution with incomplete samples and impute the missing values accordingly. In this paper, by leveraging the fact that any two batches of data with missing values come from the same data distribution, we propose to impute the missing values of two batches of samples by transforming them into a latent space through deep invertible functions and matching them distributionally. To learn the transformations and impute the missing values simultaneously, a simple and well-motivated algorithm is proposed. Our algorithm has fewer hyperparameters to fine-tune and generates high-quality imputations regardless of how missing values are generated. Extensive experiments over a large number of datasets and competing benchmark algorithms show that our method achieves state-of-the-art performance.