Monotonicity and Double Descent in Uncertainty Estimation with Gaussian Processes
{kind=link}
Abstract
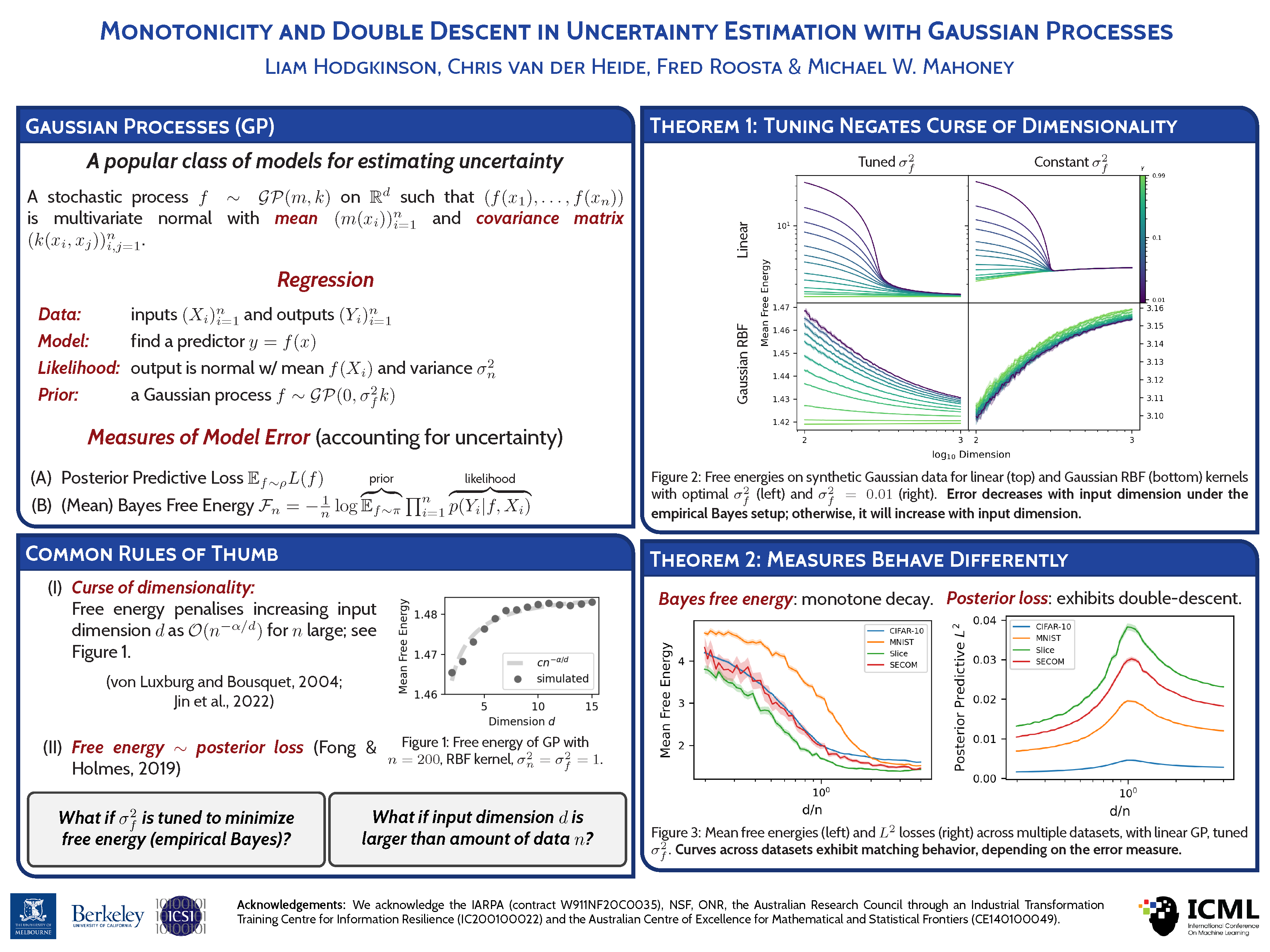
Despite their importance for assessing reliability of predictions, uncertainty quantification (UQ) measures in machine learning models have only recently begun to be rigorously characterized. One prominent issue is the curse of dimensionality: it is commonly believed that the marginal likelihood should be reminiscent of cross-validation metrics and both should deteriorate with larger input dimensions. However, we prove that by tuning hyperparameters to maximize marginal likelihood (the empirical Bayes procedure), performance, as measured by the marginal likelihood, improves monotonically with the input dimension. On the other hand, cross-validation metrics exhibit qualitatively different behavior that is characteristic of double descent. Cold posteriors, which have recently attracted interest due to their improved performance in certain settings, appear to exacerbate these phenomena. We verify empirically that our results hold for real data, beyond our considered assumptions, and we explore consequences involving synthetic covariates.