How much does Initialization Affect Generalization?
{kind=link}
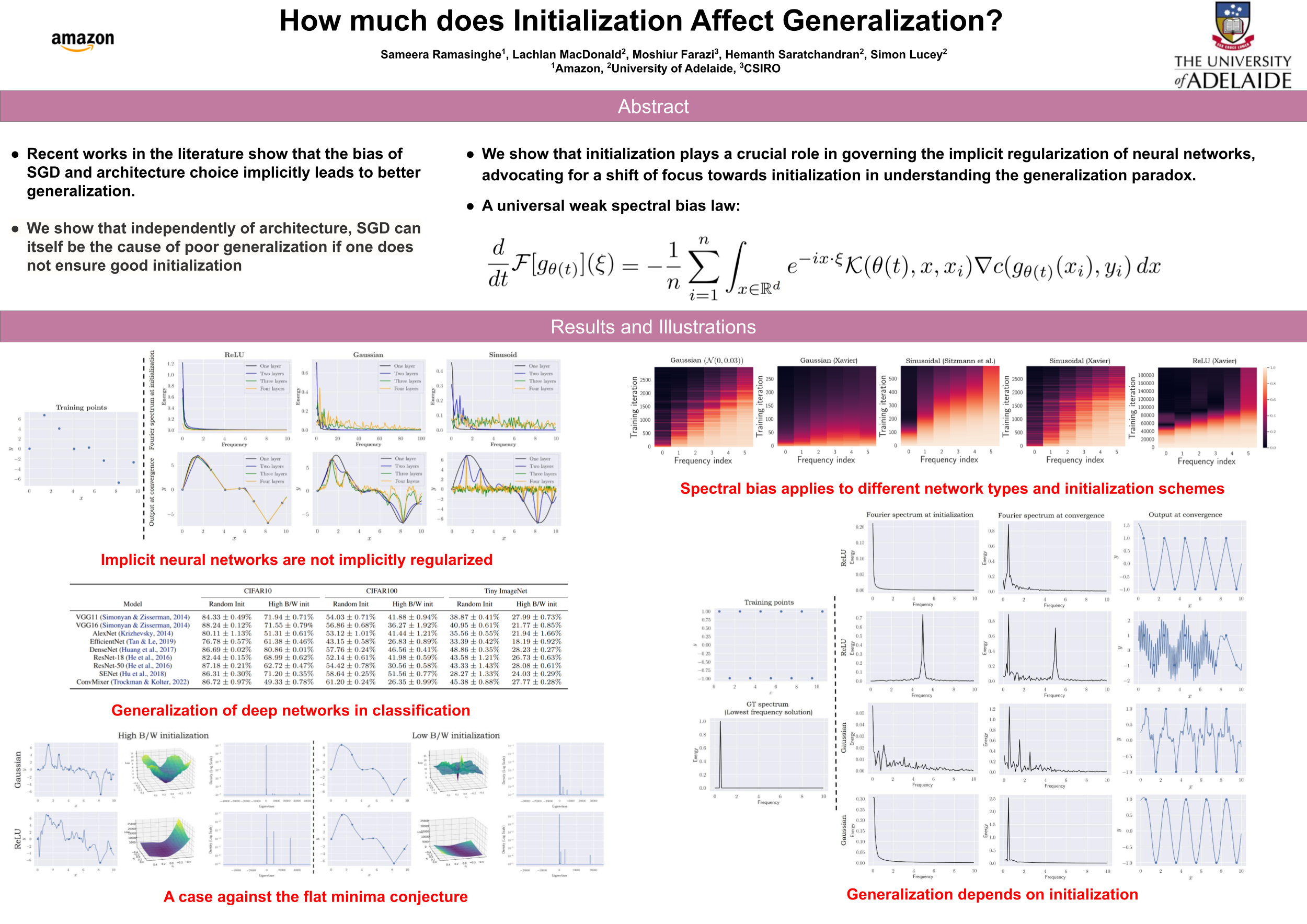
Abstract
Characterizing the remarkable generalization properties of over-parameterized neural networks remains an open problem. A growing body of recent literature shows that the bias of stochastic gradient descent (SGD) and architecture choice implicitly leads to better generalization. In this paper, we show on the contrary that, independently of architecture, SGD can itself be the cause of poor generalization if one does not ensure good initialization. Specifically, we prove that any differentiably parameterized model, trained under gradient flow, obeys a weak spectral bias law which states that sufficiently high frequencies train arbitrarily slowly. This implies that very high frequencies present at initialization will remain after training, and hamper generalization. Further, we empirically test the developed theoretical insights using practical, deep networks. Finally, we contrast our framework with that supplied by the flat-minima conjecture and show that Fourier analysis grants a more reliable framework for understanding the generalization of neural networks.