Off-Policy Average Reward Actor-Critic with Deterministic Policy Search
Naman Saxena ⋅ Subhojyoti Khastagir ⋅ Shishir Nadubettu Yadukumar ⋅ Shalabh Bhatnagar
2023 Poster
{kind=link}
Abstract
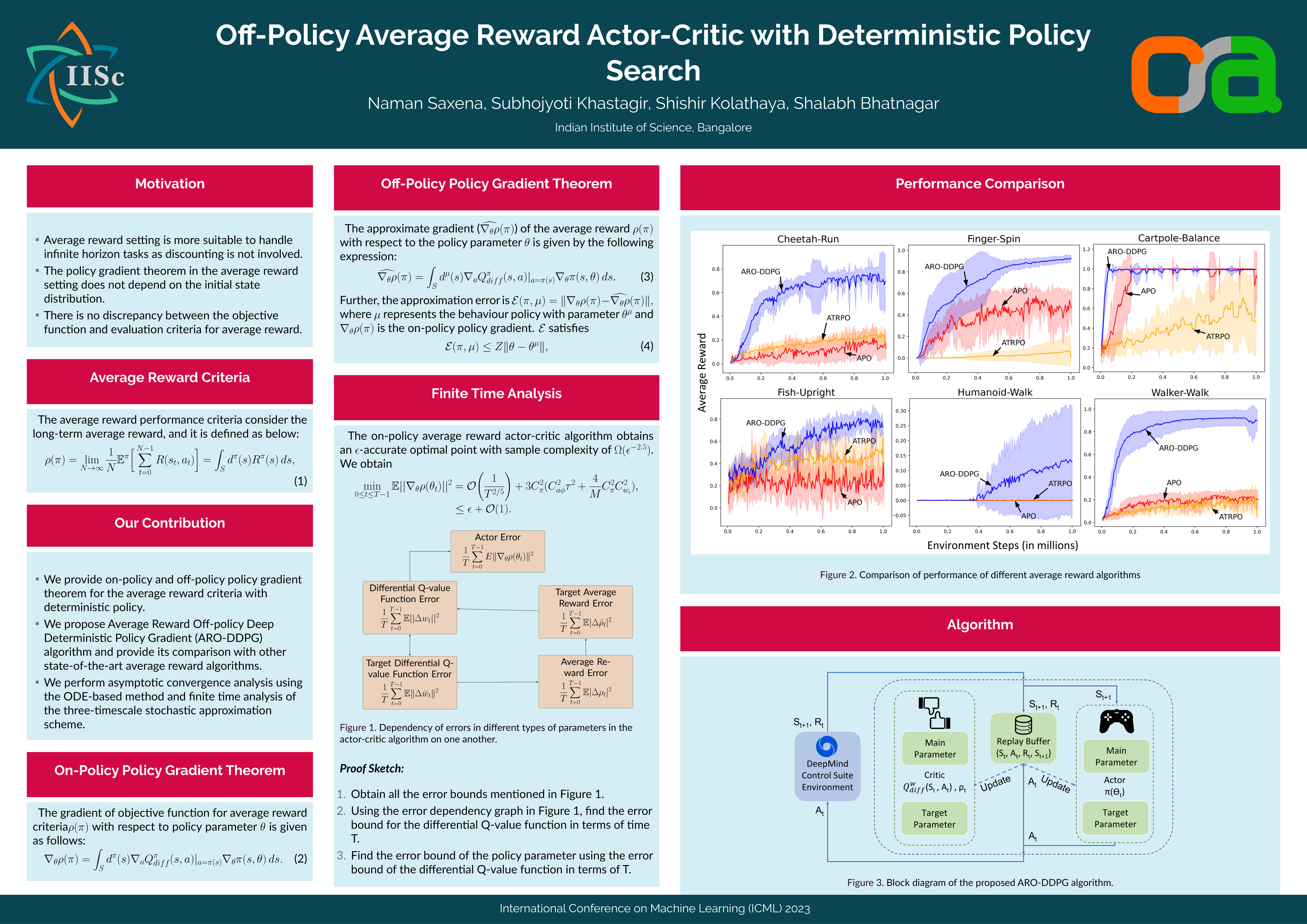
The average reward criterion is relatively less studied as most existing works in the Reinforcement Learning literature consider the discounted reward criterion. There are few recent works that present on-policy average reward actor-critic algorithms, but average reward off-policy actor-critic is relatively less explored. In this work, we present both on-policy and off-policy deterministic policy gradient theorems for the average reward performance criterion. Using these theorems, we also present an Average Reward Off-Policy Deep Deterministic Policy Gradient (ARO-DDPG) Algorithm. We first show asymptotic convergence analysis using the ODE-based method. Subsequently, we provide a finite time analysis of the resulting stochastic approximation scheme with linear function approximator and obtain an $\epsilon$-optimal stationary policy with a sample complexity of $\Omega(\epsilon^{-2.5})$. We compare the average reward performance of our proposed ARO-DDPG algorithm and observe better empirical performance compared to state-of-the-art on-policy average reward actor-critic algorithms over MuJoCo-based environments.
Video
Chat is not available.
Successful Page Load