Scaling Up Dataset Distillation to ImageNet-1K with Constant Memory
Justin Cui ⋅ Ruochen Wang ⋅ Si Si ⋅ Cho-Jui Hsieh
2023 Poster
{kind=link}
Abstract
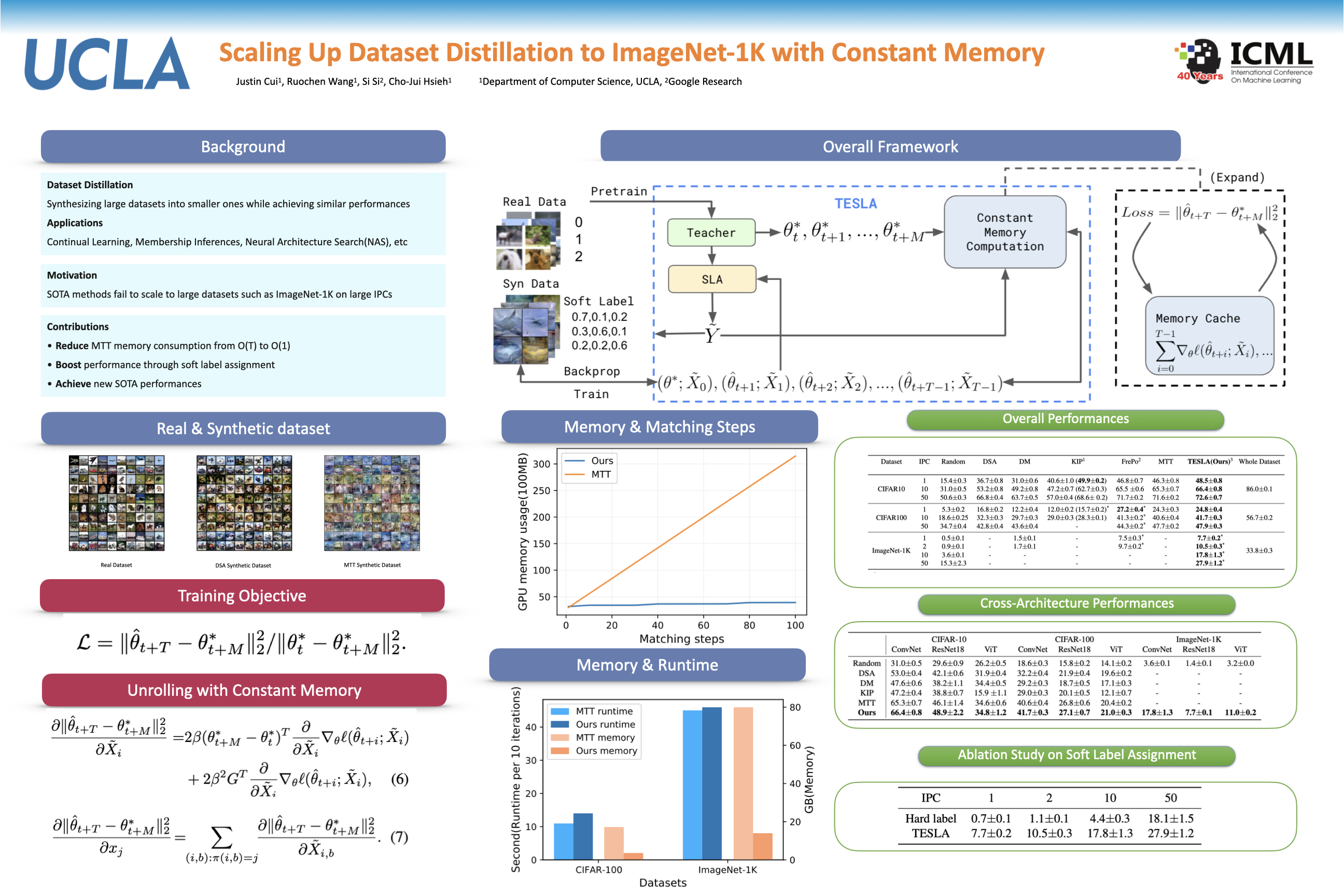
Dataset Distillation is a newly emerging area that aims to distill large datasets into much smaller and highly informative synthetic ones to accelerate training and reduce storage. Among various dataset distillation methods, trajectory-matching-based methods (MTT) have achieved SOTA performance in many tasks, e.g., on CIFAR-10/100. However, due to exorbitant memory consumption when unrolling optimization through SGD steps, MTT fails to scale to large-scale datasets such as ImageNet-1K. Can we scale this SOTA method to ImageNet-1K and does its effectiveness on CIFAR transfer to ImageNet-1K? To answer these questions, we first propose a procedure to exactly compute the unrolled gradient with constant memory complexity, which allows us to scale MTT to ImageNet-1K seamlessly with $\sim 6$x reduction in memory footprint. We further discover that it is challenging for MTT to handle datasets with a large number of classes, and propose a novel soft label assignment that drastically improves its convergence. The resulting algorithm sets new SOTA on ImageNet-1K: we can scale up to 50 IPCs (Image Per Class) on ImageNet-1K on a single GPU (all previous methods can only scale to 2 IPCs on ImageNet-1K), leading to the best accuracy (only 5.9% accuracy drop against full dataset training) while utilizing only 4.2% of the number of data points - an 18.2% absolute gain over prior SOTA.
Video
Chat is not available.
Successful Page Load