Contextual Reliability: When Different Features Matter in Different Contexts
{kind=link}
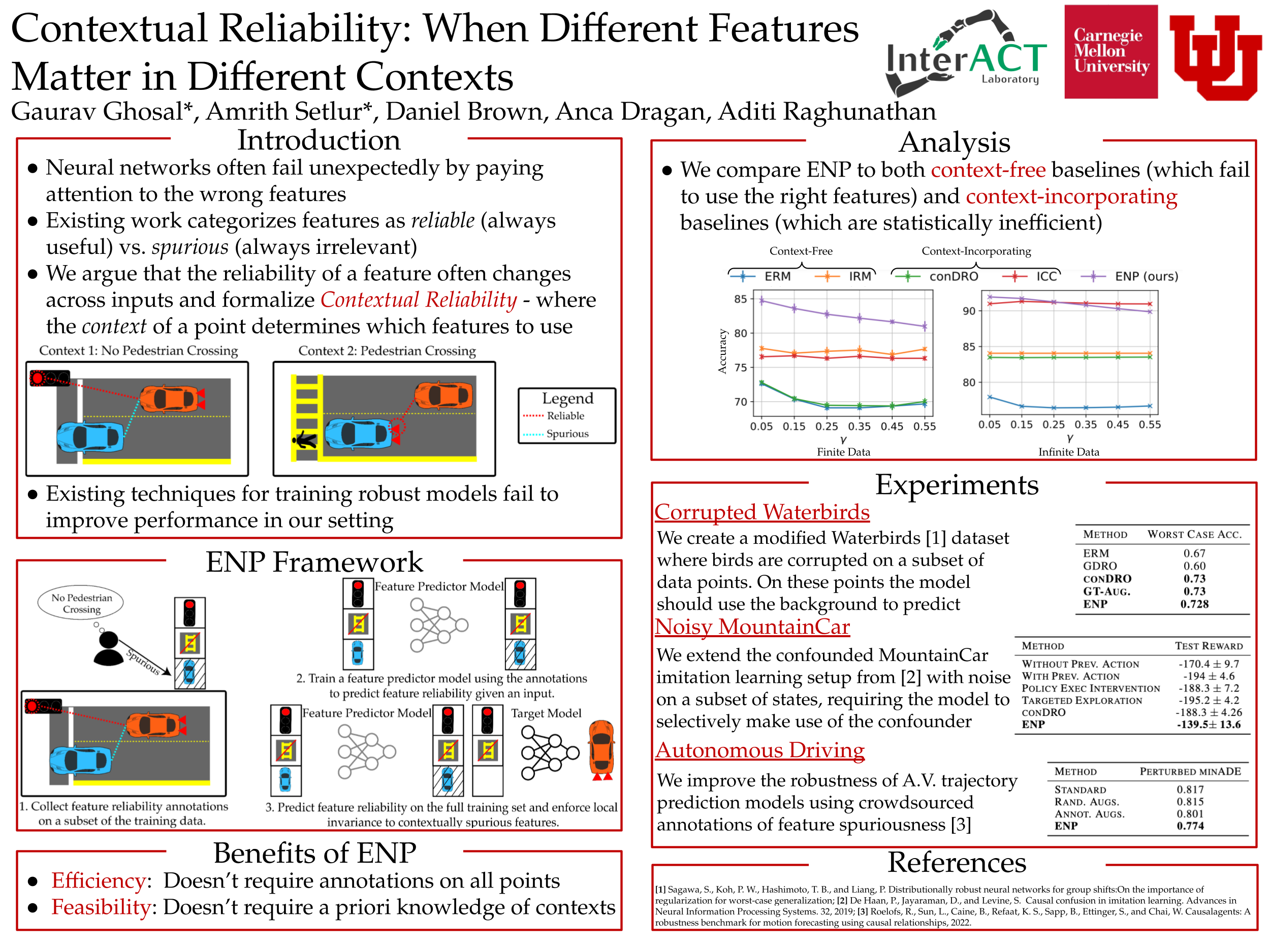
Abstract
Deep neural networks often fail catastrophically by relying on spurious correlations. Most prior work assumes a clear dichotomy into spurious and reliable features; however, this is often unrealistic. For example, most of the time we do not want an autonomous car to simply copy the speed of surrounding cars---we don't want our car to run a red light if a neighboring car does so. However, we cannot simply enforce invariance to next-lane speed, since it could provide valuable information about an unobservable pedestrian at a crosswalk. Thus, universally ignoring features that are sometimes (but not always) reliable can lead to non-robust performance. We formalize a new setting called contextual reliability which accounts for the fact that the "right" features to use may vary depending on the context. We propose and analyze a two-stage framework called Explicit Non-spurious feature Prediction (ENP) which first identifies the relevant features to use for a given context, then trains a model to rely exclusively on these features. Our work theoretically and empirically demonstrates the advantages of ENP over existing methods and provides new benchmarks for contextual reliability.