Parameterized projected Bellman operator
{kind=link}
Abstract
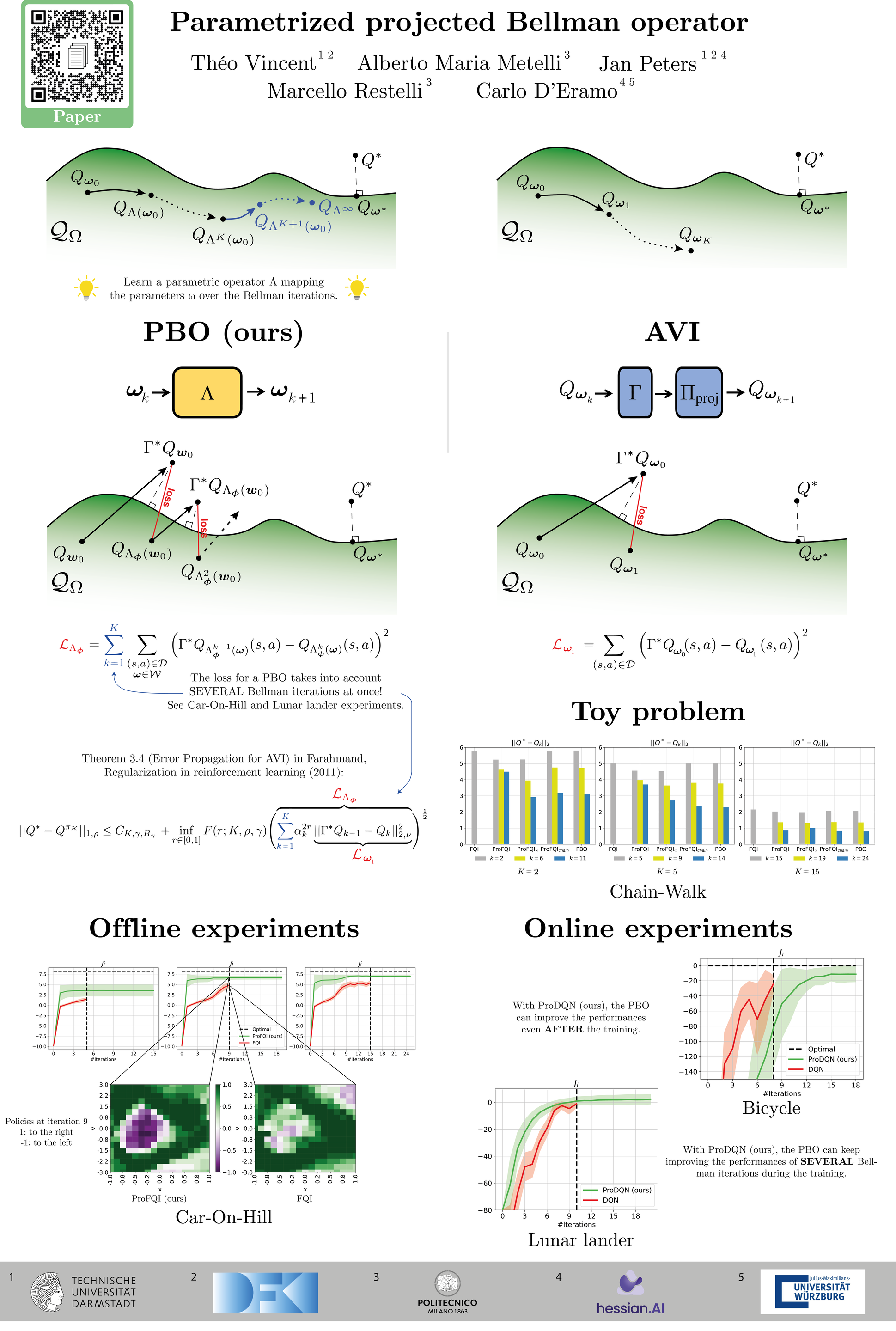
The Bellman operator is a cornerstone of reinforcement learning (RL), widely used from traditional value-based methods to modern actor-critic approaches. In problems with unknown models, the Bellman operator is estimated via transition samples that strongly determine its behavior, as uninformative samples can result in negligible updates or long detours before reaching the fixed point. In this paper, we introduce the novel idea of an operator that acts on the parameters of action-value function approximators. Our novel operator can obtain a sequence of action-value function parameters that progressively approaches the ones of the optimal action-value function. This means that we merge the traditional two-step procedure consisting of applying the Bellman operator and subsequently projecting onto the space of action-value function. For this reason, we call our novel operator projected Bellman operator (PBO). We formulate an optimization problem to learn PBOs for generic sequential decision-making problems, and we analyze the PBO properties in two representative classes of RL problems. Furthermore, we study the use of PBO under the lens of the approximate value iteration framework, devising algorithmic implementations to learn PBOs in both offline and online settings resorting to neural network regression. Eventually, we empirically evince how PBO can overcome the limitations of classical methods, opening up new research directions as a novel paradigm in RL.