Offline Goal-Conditioned RL with Latent States as Actions
{kind=link}
Abstract
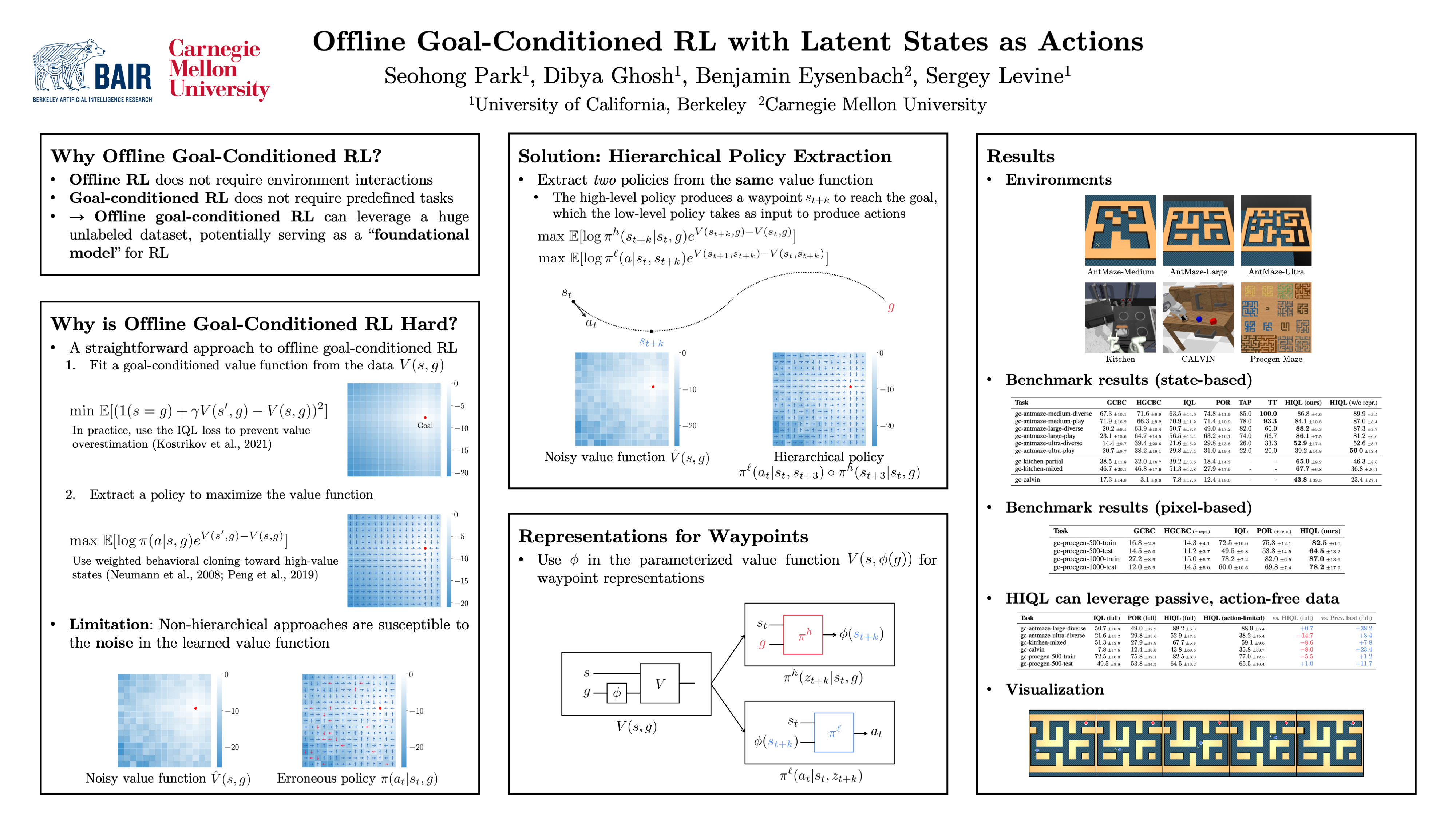
In the same way that unsupervised pre-training has become the bedrock for computer vision and NLP, goal-conditioned RL might provide a similar strategy for making use of vast quantities of unlabeled (reward-free) data. However, building effective algorithms for goal-conditioned RL, ones that can learn directly from offline data, is challenging because it is hard to accurately estimate the exact state value of reaching faraway goals. Nonetheless, goal-reaching problems exhibit structure – reaching a distant goal entails visiting some closer states (or representations thereof) first. Importantly, it is easier to assess the effect of actions on getting to these closer states. Based on this idea, we propose a hierarchical algorithm for goal-conditioned RL from offline data. Using one action-free value function, we learn two policies that allow us to exploit this structure: a high-level policy that predicts (a representation of) a waypoint, and a low-level policy that predicts the action for reaching this waypoint. Through analysis and didactic examples, we show how this hierarchical decomposition makes our method robust to noise in the estimated value function. We then apply our method to offline goal-reaching benchmarks, showing that our method can solve long-horizon tasks that stymie prior methods, can scale to high-dimensional image observations, and can readily make use of action-free data.