Learning to Optimize with Recurrent Hierarchical Transformers
{kind=link}
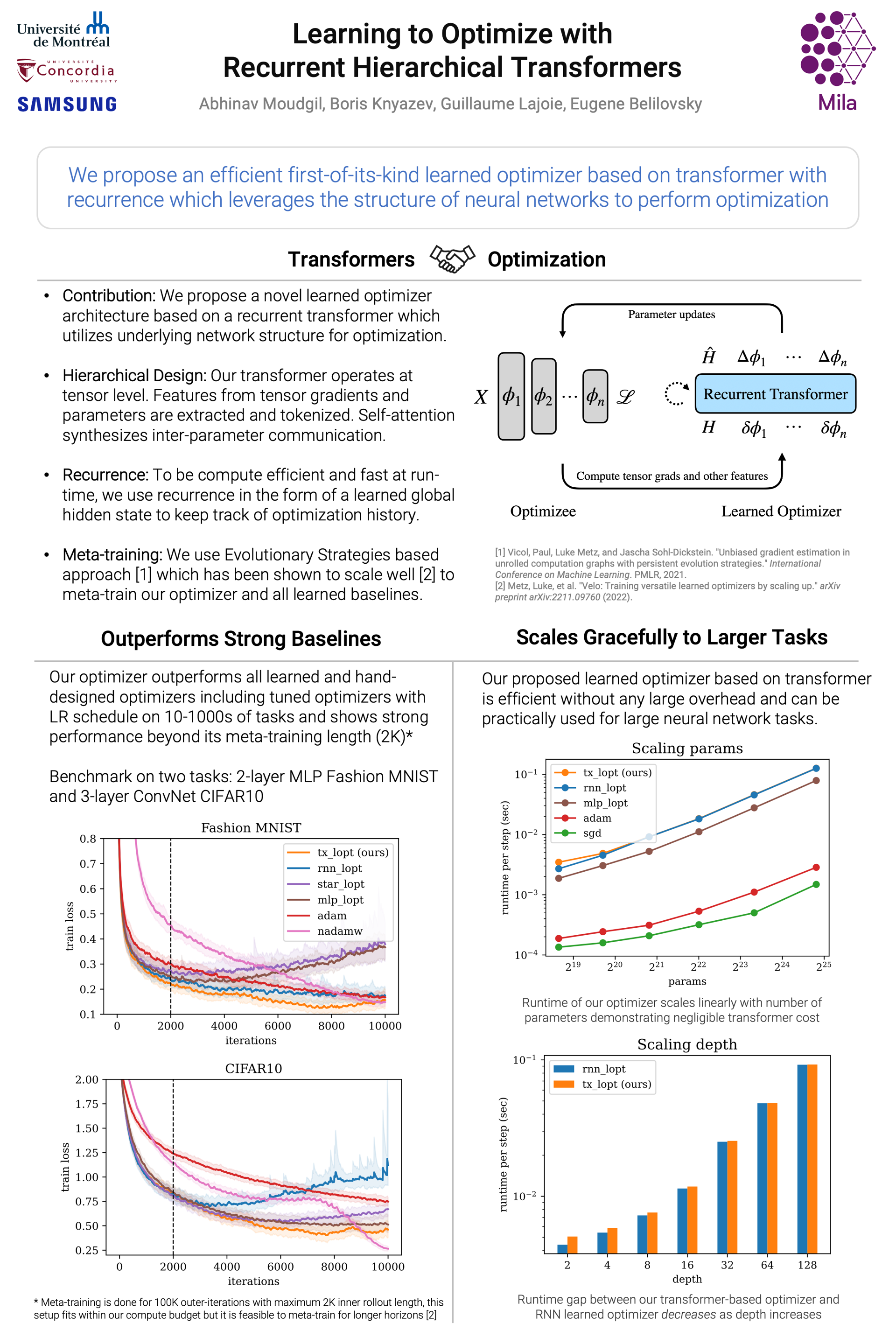
Abstract
Learning to optimize (L2O) has received a lot of attention recently because of its potential to leverage data to outperform hand-designed optimization algorithms such as Adam. Typically, these learned optimizers are meta-learned on optimization tasks to achieve rapid convergence. However, they can suffer from high meta-training costs and memory overhead. Recent attempts have been made to reduce the computational costs of these learned optimizers by introducing a hierarchy that enables them to perform most of the heavy computation at the tensor (layer) level rather than the parameter level. This not only leads to sublinear memory cost with respect to number of parameters, but also allows for a higher representation capacity for efficient learned optimization. To this end, we propose an efficient transformer-based learned optimizer which facilitates communication among tensors with self-attention and keeps track of optimization history with recurrence. We show that our optimizer learns to optimize better than strong learned optimizer baselines at a comparable memory overhead, thereby suggesting encouraging scaling trends.