Simplex Neural Population Learning: Any-Mixture Bayes-Optimality in Symmetric Zero-sum Games
{kind=link}
Abstract
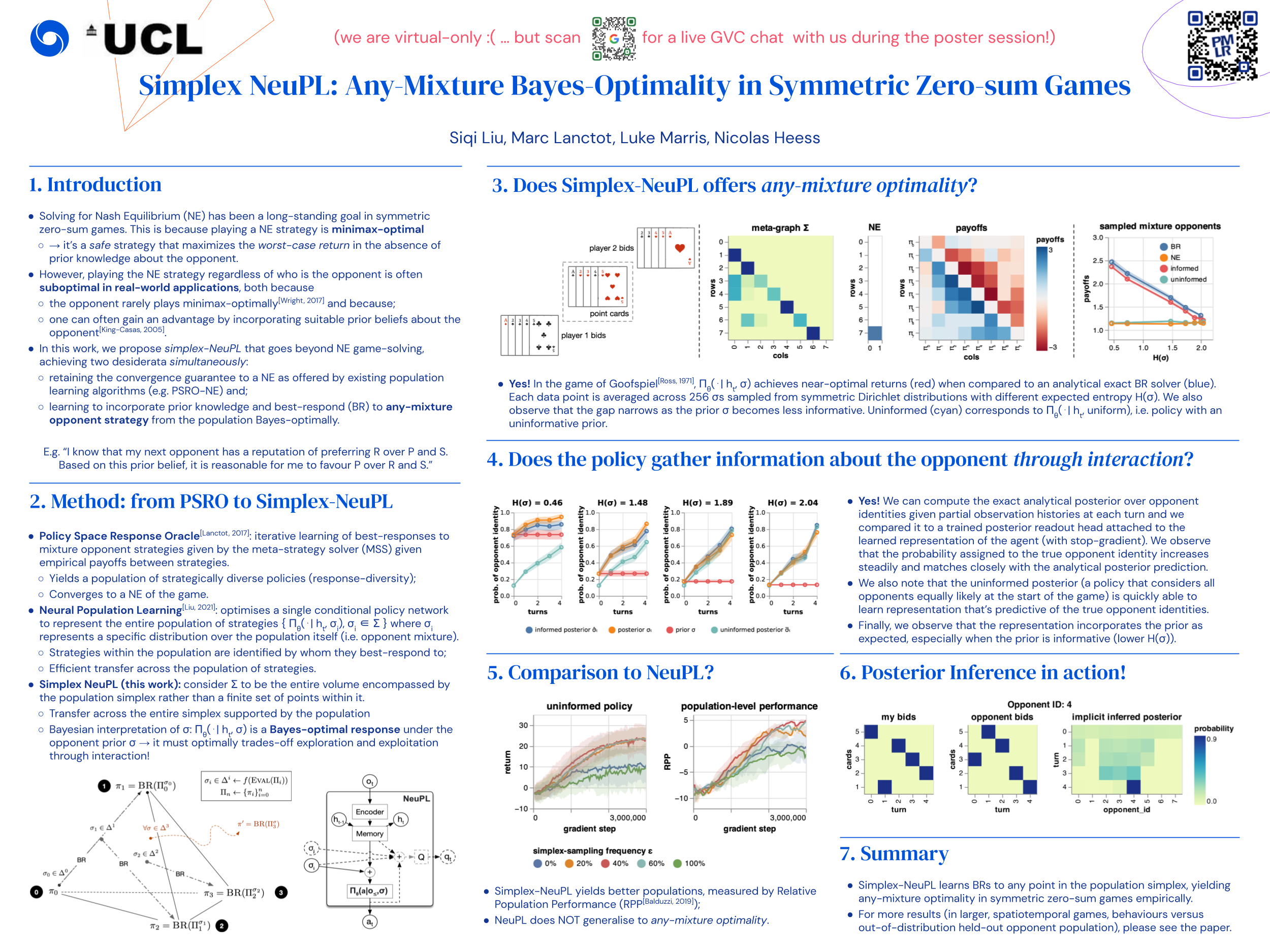
Learning to play optimally against any mixture over a diverse set of strategies is of important practical interests in competitive games. In this paper, we propose simplex-NeuPL that satisfies two desiderata simultaneously: i) learning a population of strategically diverse basis policies, represented by a single conditional network; ii) using the same network, learn best-responses to any mixture over the simplex of basis policies. We show that the resulting conditional policies incorporate prior information about their opponents effectively, enabling near optimal returns against arbitrary mixture policies in a game with tractable best-responses. We verify that such policies behave Bayes-optimally under uncertainty and offer insights in using this flexibility at test time. Finally, we offer evidence that learning best-responses to any mixture policies is an effective auxiliary task for strategic exploration, which, by itself, can lead to more performant populations.