Goal Misgeneralization in Deep Reinforcement Learning
Lauro Langosco di Langosco ⋅ Jack Koch ⋅ Lee Sharkey ⋅ Jacob Pfau ⋅ David Krueger
Keywords:
DL: Robustness
SA: Everything Else
SA: Fairness, Equity, Justice and Safety
RL: Deep RL
Deep Learning
RL: Inverse
DL: Everything Else
RL: Everything Else
2022 Poster
{kind=link}
Abstract
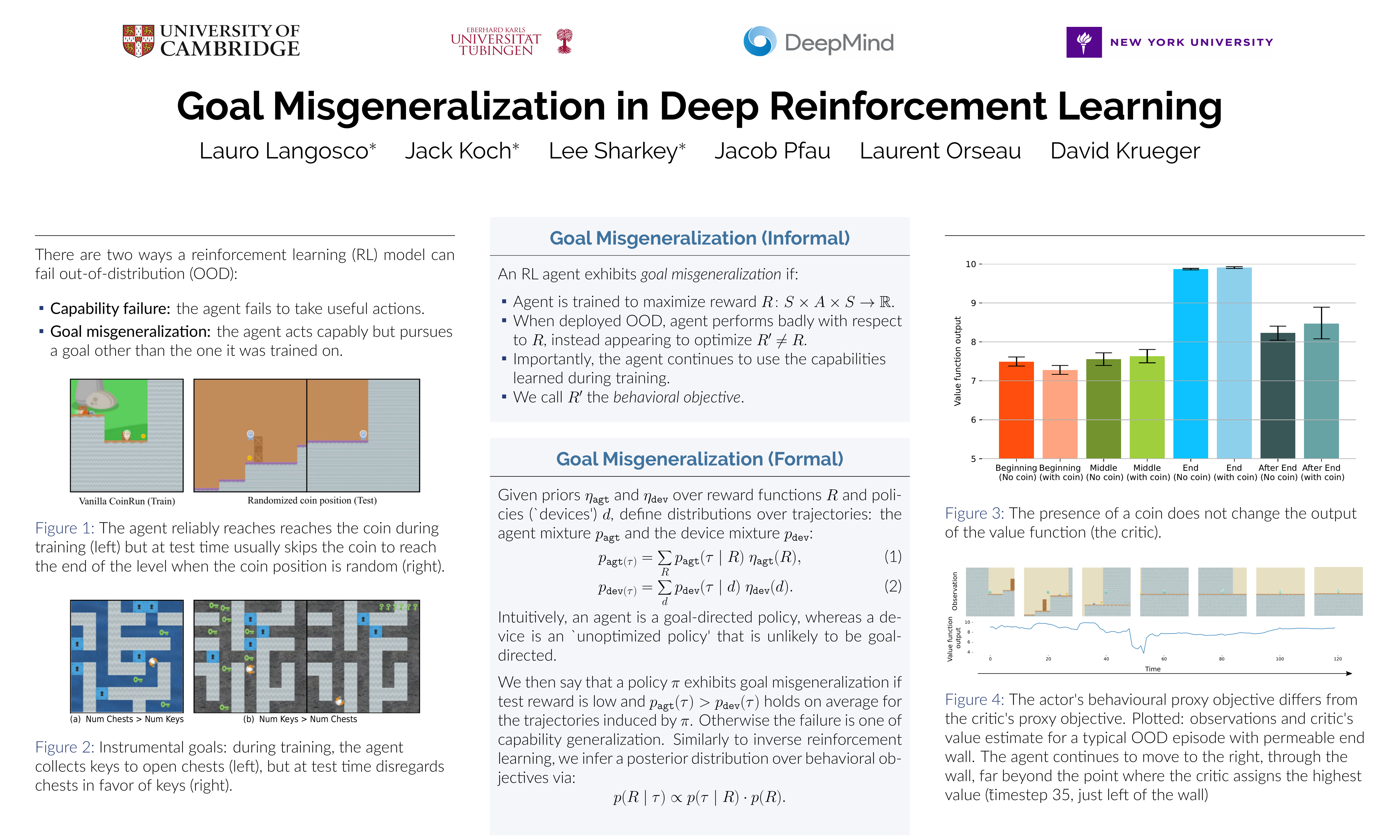
We study \emph{goal misgeneralization}, a type of out-of-distribution robustness failure in reinforcement learning (RL). Goal misgeneralization occurs when an RL agent retains its capabilities out-of-distribution yet pursues the wrong goal. For instance, an agent might continue to competently avoid obstacles, but navigate to the wrong place. In contrast, previous works have typically focused on capability generalization failures, where an agent fails to do anything sensible at test time.We provide the first explicit empirical demonstrations of goal misgeneralization and present a partial characterization of its causes.
Chat is not available.
Successful Page Load