ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers
{kind=link}
Abstract
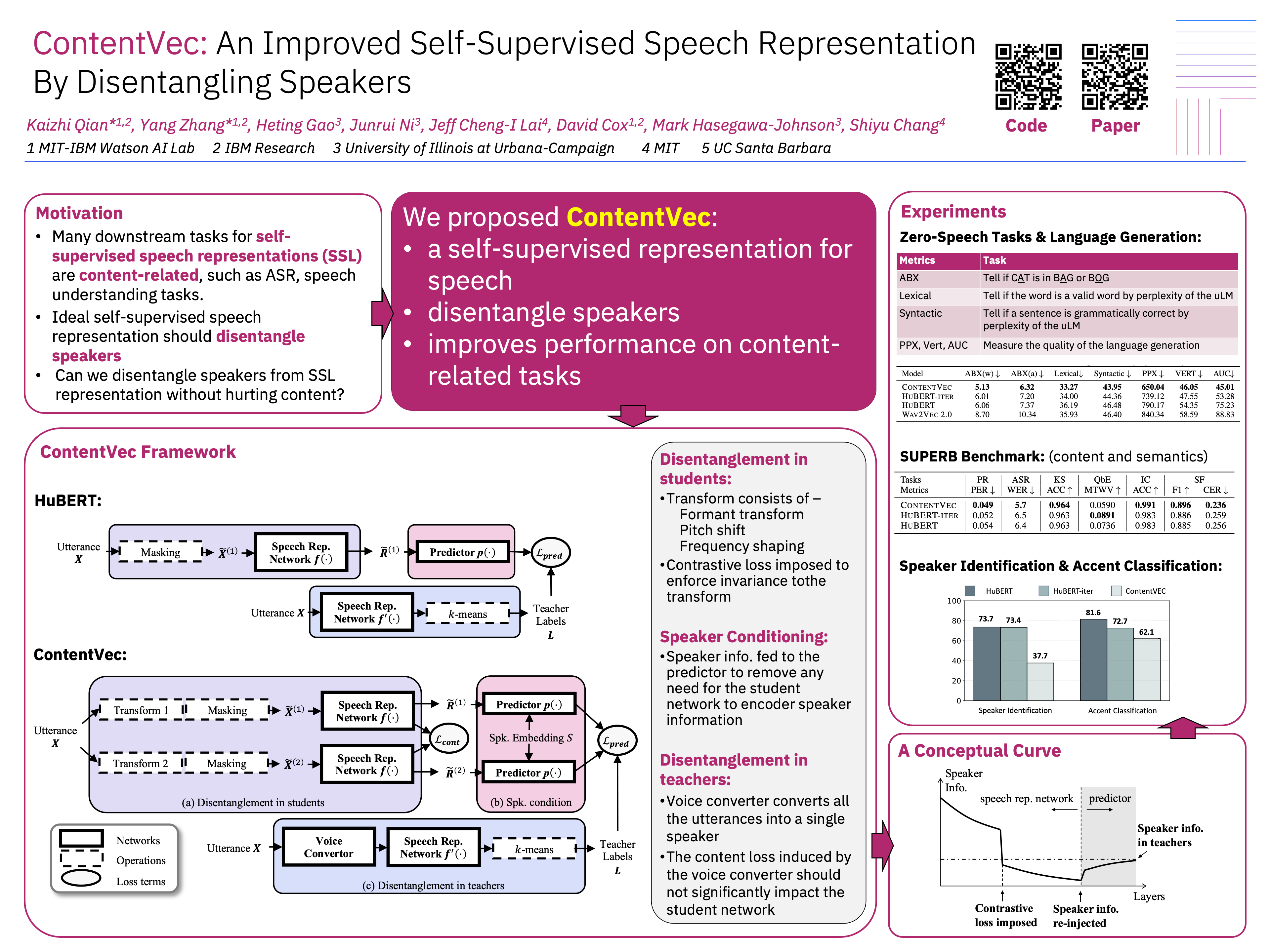
Self-supervised learning in speech involves training a speech representation network on a large-scale unannotated speech corpus, and then applying the learned representations to downstream tasks. Since the majority of the downstream tasks of SSL learning in speech largely focus on the content information in speech, the most desirable speech representations should be able to disentangle unwanted variations, such as speaker variations, from the content. However, disentangling speakers is very challenging, because removing the speaker information could easily result in a loss of content as well, and the damage of the latter usually far outweighs the benefit of the former. In this paper, we propose a new SSL method that can achieve speaker disentanglement without severe loss of content. Our approach is adapted from the HuBERT framework, and incorporates disentangling mechanisms to regularize both the teacher labels and the learned representations. We evaluate the benefit of speaker disentanglement on a set of content-related downstream tasks, and observe a consistent and notable performance advantage of our speaker-disentangled representations.