Adapting the Linearised Laplace Model Evidence for Modern Deep Learning
{kind=link}
Abstract
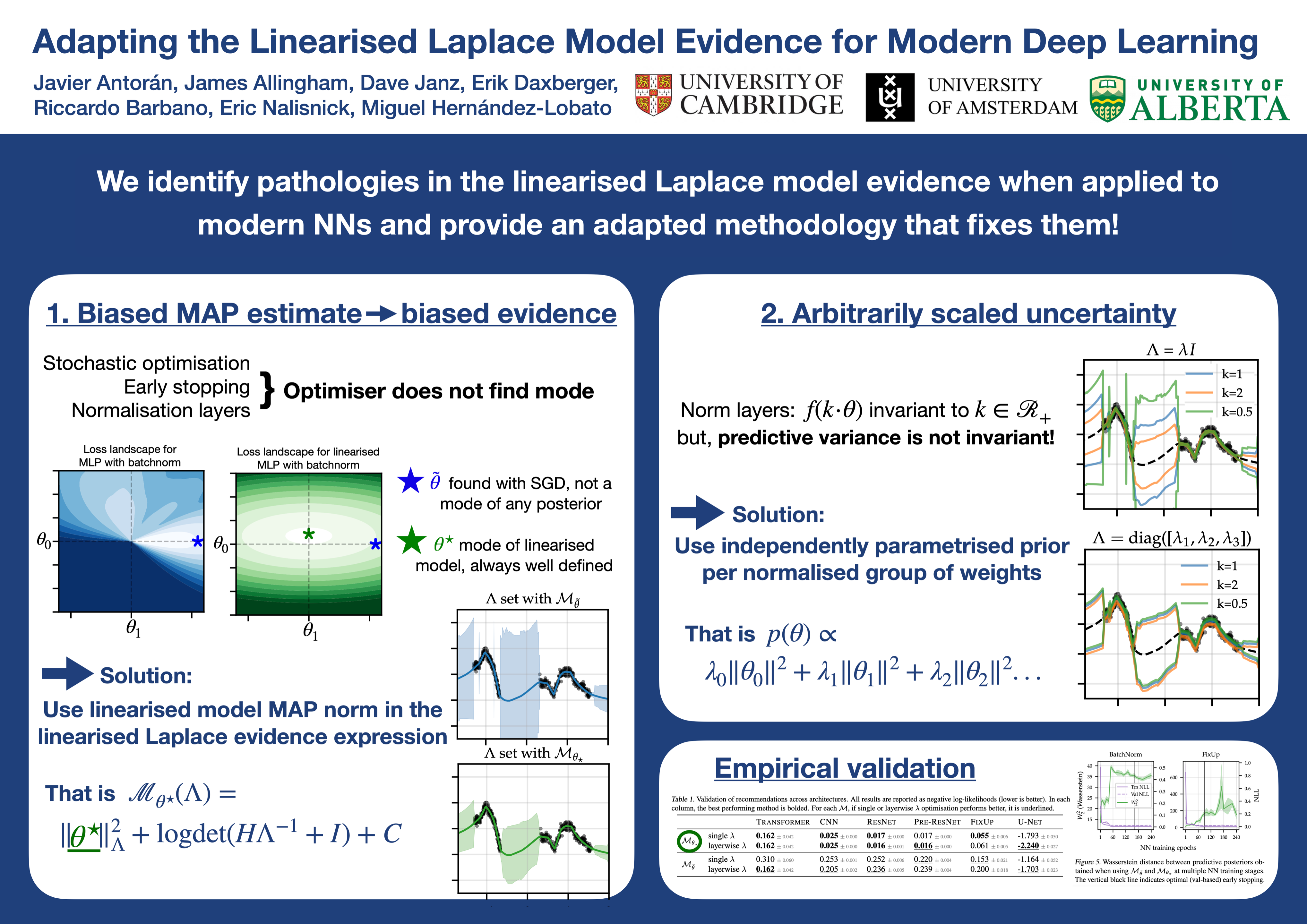
The linearised Laplace method for estimating model uncertainty has received renewed attention in the Bayesian deep learning community. The method provides reliable error bars and admits a closed-form expression for the model evidence, allowing for scalable selection of model hyperparameters. In this work, we examine the assumptions behind this method, particularly in conjunction with model selection.We show that these interact poorly with some now-standard tools of deep learning--stochastic approximation methods and normalisation layers--and make recommendations for how to better adapt this classic method to the modern setting.We provide theoretical support for our recommendations and validate them empirically on MLPs, classic CNNs, residual networks with and without normalisation layers, generative autoencoders and transformers.