Model-Value Inconsistency as a Signal for Epistemic Uncertainty
{kind=link}
Abstract
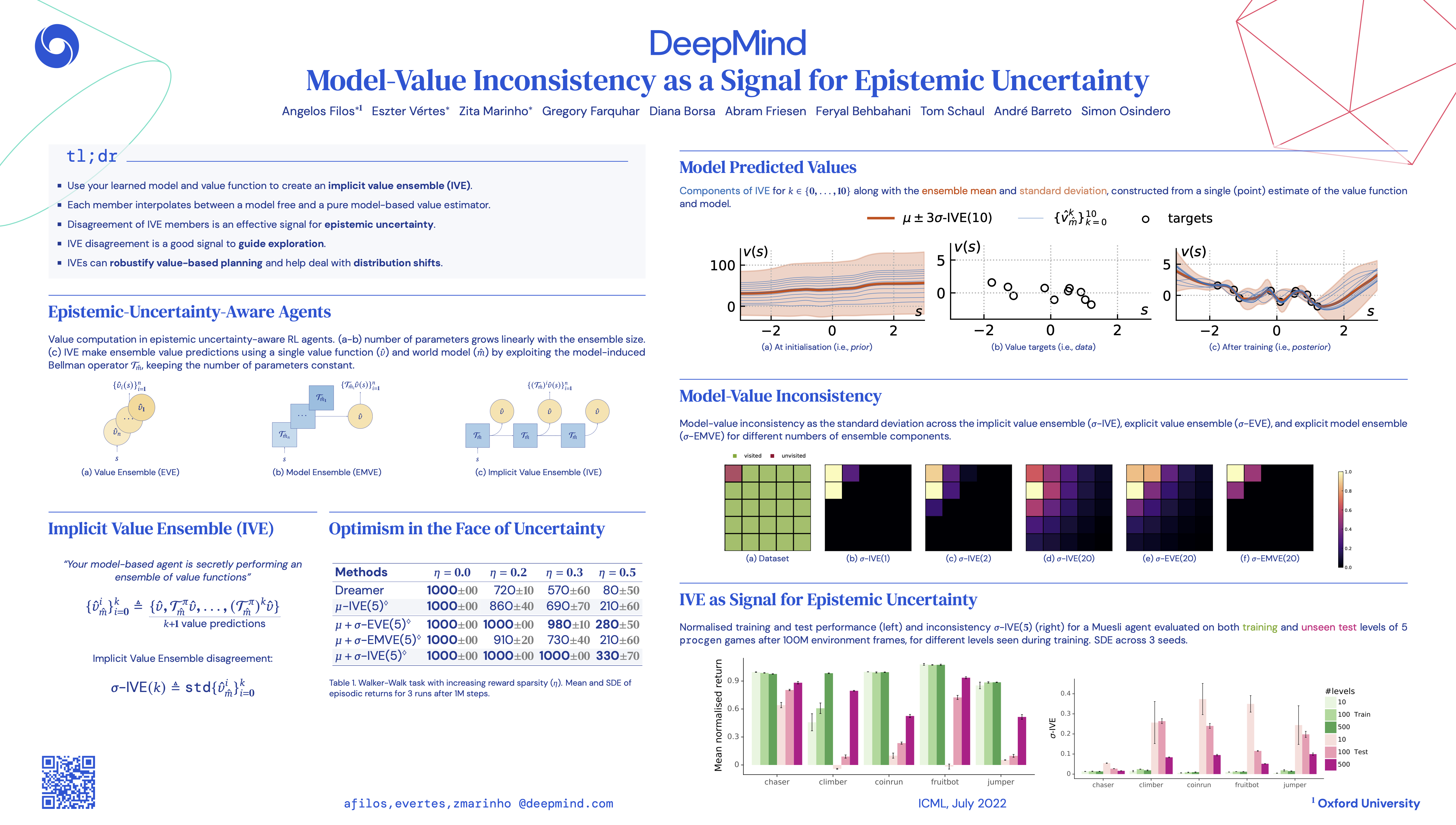
Using a model of the environment and a value function, an agent can construct many estimates of a state’s value, by unrolling the model for different lengths and bootstrapping with its value function. Our key insight is that one can treat this set of value estimates as a type of ensemble, which we call an implicit value ensemble (IVE). Consequently, the discrepancy between these estimates can be used as a proxy for the agent’s epistemic uncertainty; we term this signal model-value inconsistency or self-inconsistency for short. Unlike prior work which estimates uncertainty by training an ensemble of many models and/or value functions, this approach requires only the single model and value function which are already being learned in most model-based reinforcement learning algorithms. We provide empirical evidence in both tabular and function approximation settings from pixels that self-inconsistency is useful (i) as a signal for exploration, (ii) for acting safely under distribution shifts, and (iii) for robustifying value-based planning with a learned model.