UNIREX: A Unified Learning Framework for Language Model Rationale Extraction
{kind=link}
Abstract
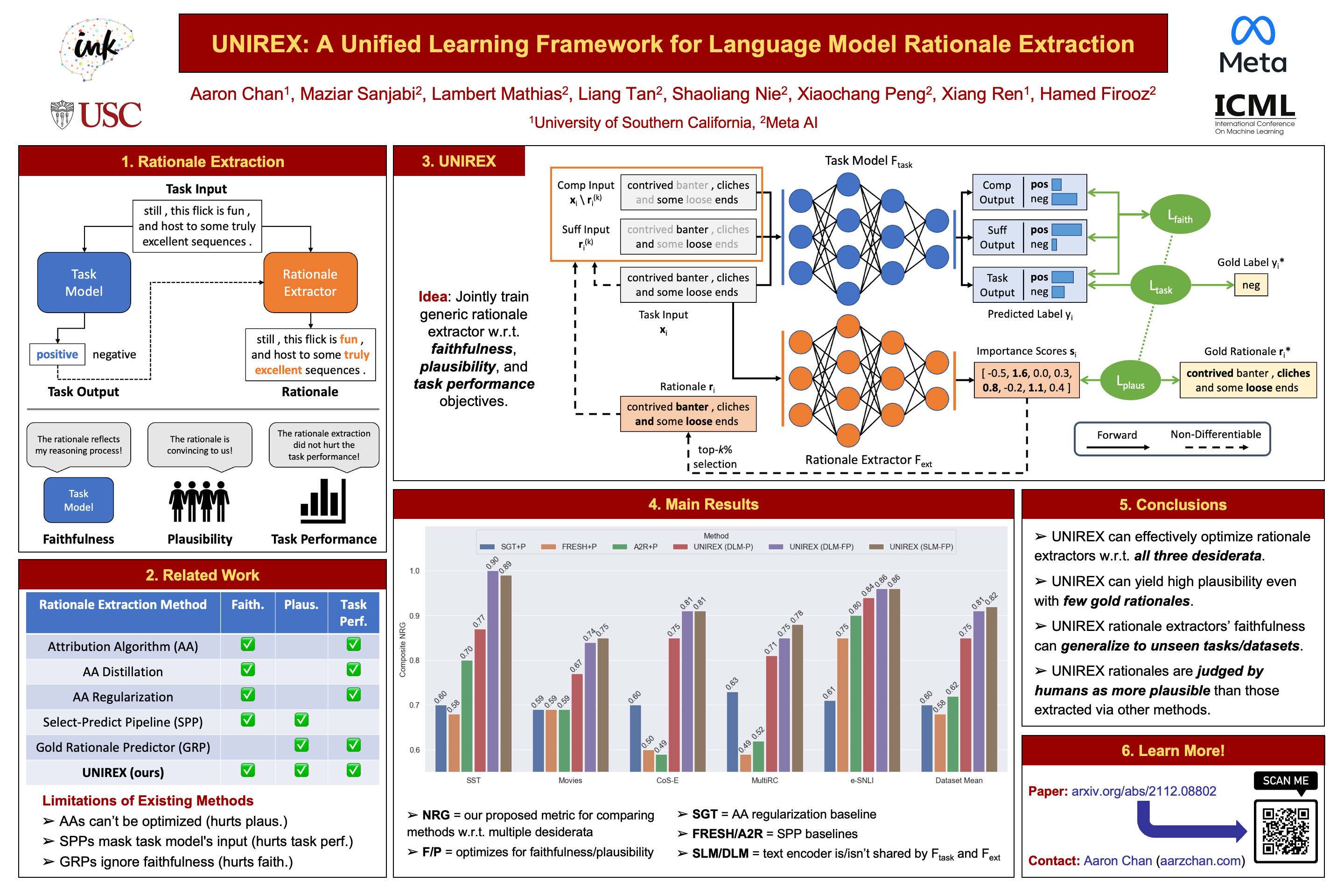
An extractive rationale explains a language model's (LM's) prediction on a given task instance by highlighting the text inputs that most influenced the prediction. Ideally, rationale extraction should be faithful (reflective of LM's actual behavior) and plausible (convincing to humans), without compromising the LM's (i.e., task model's) task performance. Although attribution algorithms and select-predict pipelines are commonly used in rationale extraction, they both rely on certain heuristics that hinder them from satisfying all three desiderata. In light of this, we propose UNIREX, a flexible learning framework which generalizes rationale extractor optimization as follows: (1) specify architecture for a learned rationale extractor; (2) select explainability objectives (\ie faithfulness and plausibility criteria); and (3) jointly train the task model and rationale extractor on the task using selected objectives. UNIREX enables replacing prior works' heuristic design choices with a generic learned rationale extractor in (1) and optimizing it for all three desiderata in (2)-(3). To facilitate comparison between methods w.r.t. multiple desiderata, we introduce the Normalized Relative Gain (NRG) metric. On five English text classification datasets, our best UNIREX configuration outperforms baselines by an average of 32.9% NRG.Plus, UNIREX rationale extractors' faithfulness can even generalize to unseen datasets and tasks.