Reverse Engineering the Neural Tangent Kernel
{kind=link}
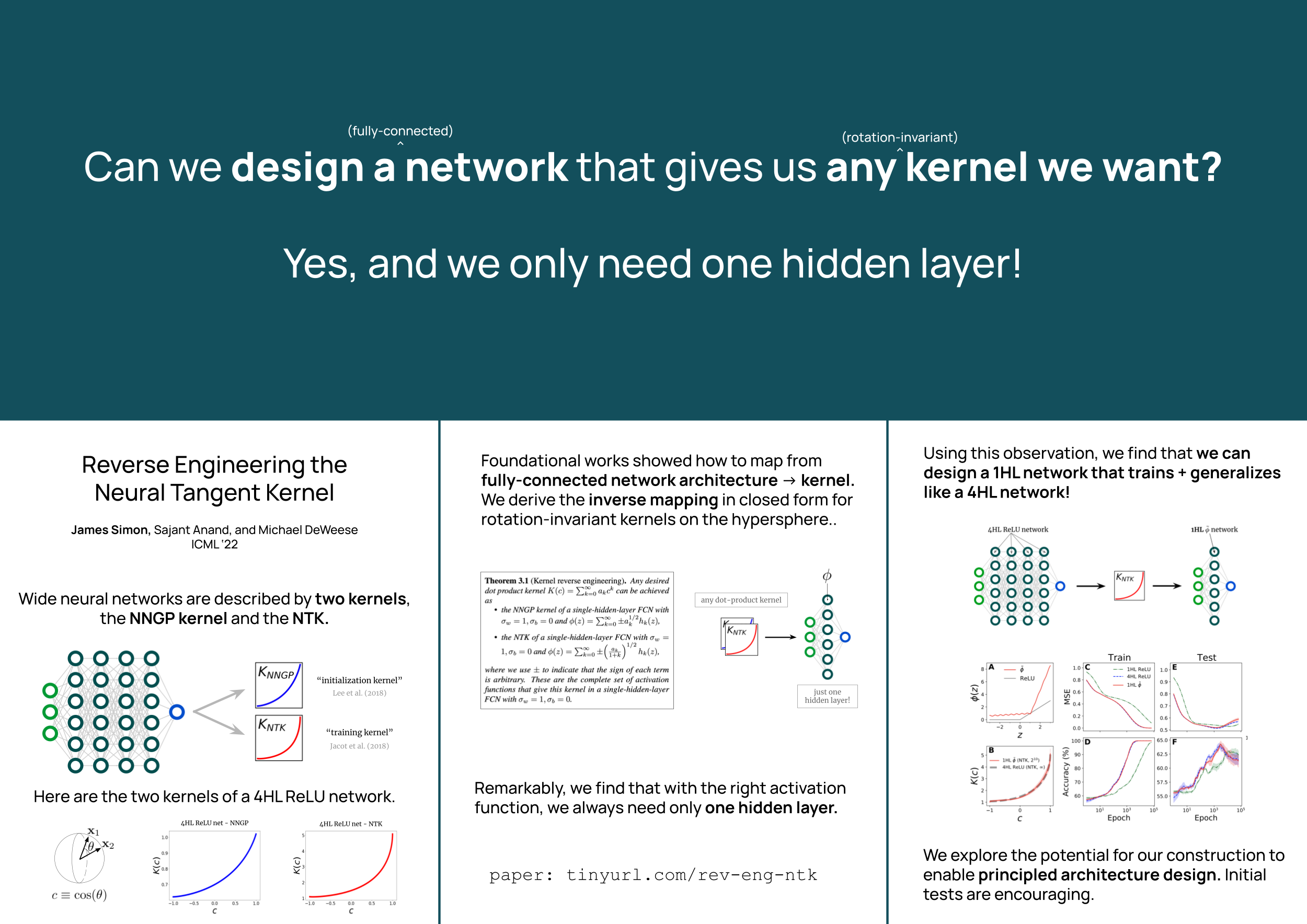
Abstract
The development of methods to guide the design of neural networks is an important open challenge for deep learning theory. As a paradigm for principled neural architecture design, we propose the translation of high-performing kernels, which are better-understood and amenable to first-principles design, into equivalent network architectures, which have superior efficiency, flexibility, and feature learning. To this end, we constructively prove that, with just an appropriate choice of activation function, any positive-semidefinite dot-product kernel can be realized as either the NNGP or neural tangent kernel of a fully-connected neural network with only one hidden layer. We verify our construction numerically and demonstrate its utility as a design tool for finite fully-connected networks in several experiments.