Efficient Representation Learning via Adaptive Context Pooling
{kind=link}
Abstract
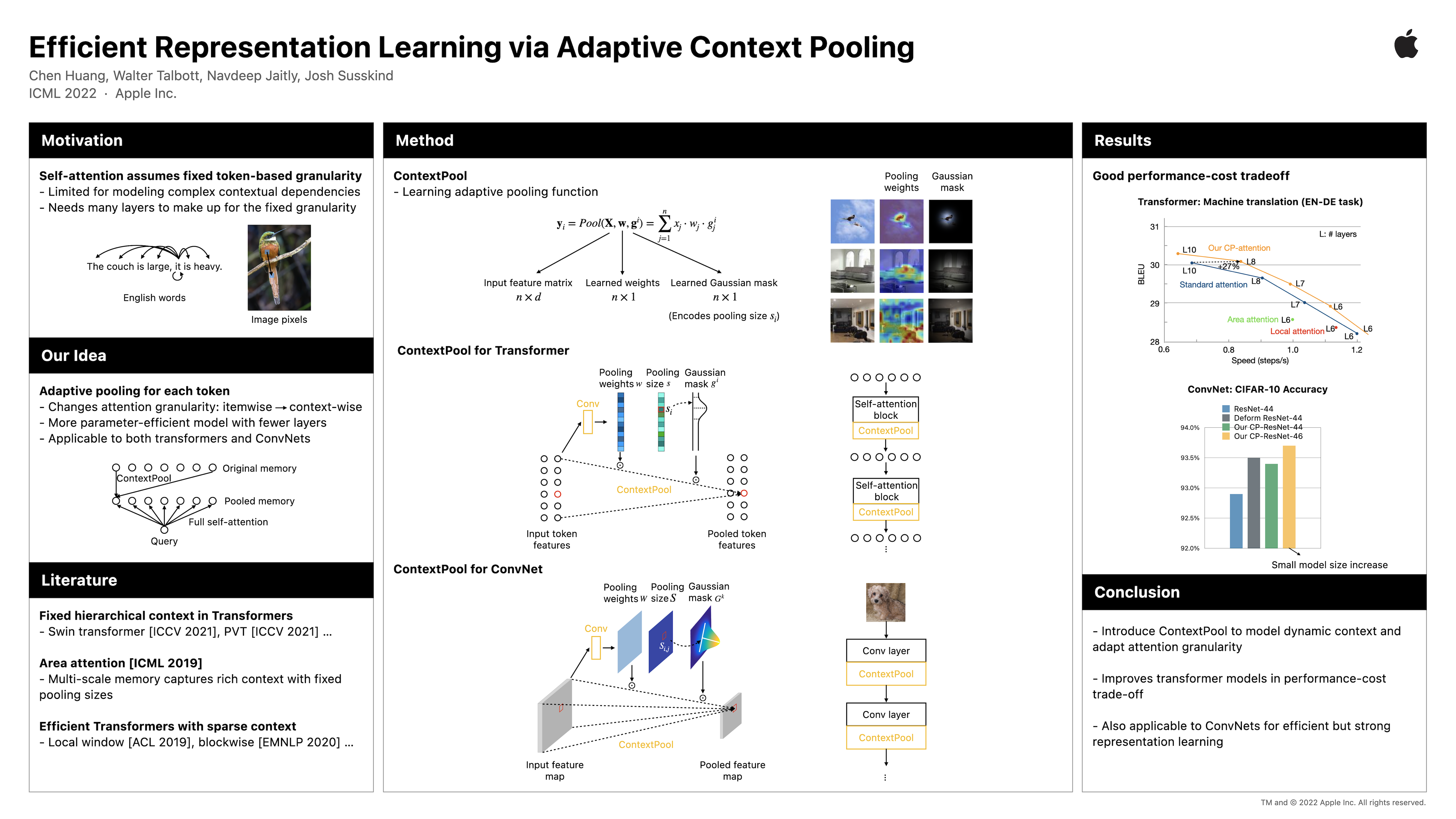
Self-attention mechanisms model long-range context by using pairwise attention between all input tokens. In doing so, they assume a fixed attention granularity defined by the individual tokens (e.g., text characters or image pixels), which may not be optimal for modeling complex dependencies at higher levels. In this paper, we propose ContextPool to address this problem by adapting the attention granularity for each token. Inspired by the success of ConvNets that are combined with pooling to capture long-range dependencies, we learn to pool neighboring features for each token before computing attention in a given attention layer. The pooling weights and support size are adaptively determined, allowing the pooled features to encode meaningful context with varying scale. We show that ContextPool makes attention models more expressive, achieving strong performance often with fewer layers and thus significantly reduced cost. Experiments validate that our ContextPool module, when plugged into transformer models, matches or surpasses state-of-the-art performance using less compute on several language and image benchmarks, outperforms recent works with learned context sizes or sparse attention patterns, and is also applicable to ConvNets for efficient feature learning.