A Model-Agnostic Randomized Learning Framework based on Random Hypothesis Subspace Sampling
Yiting Cao ⋅ Chao Lan
2022 Poster
{kind=link}
Abstract
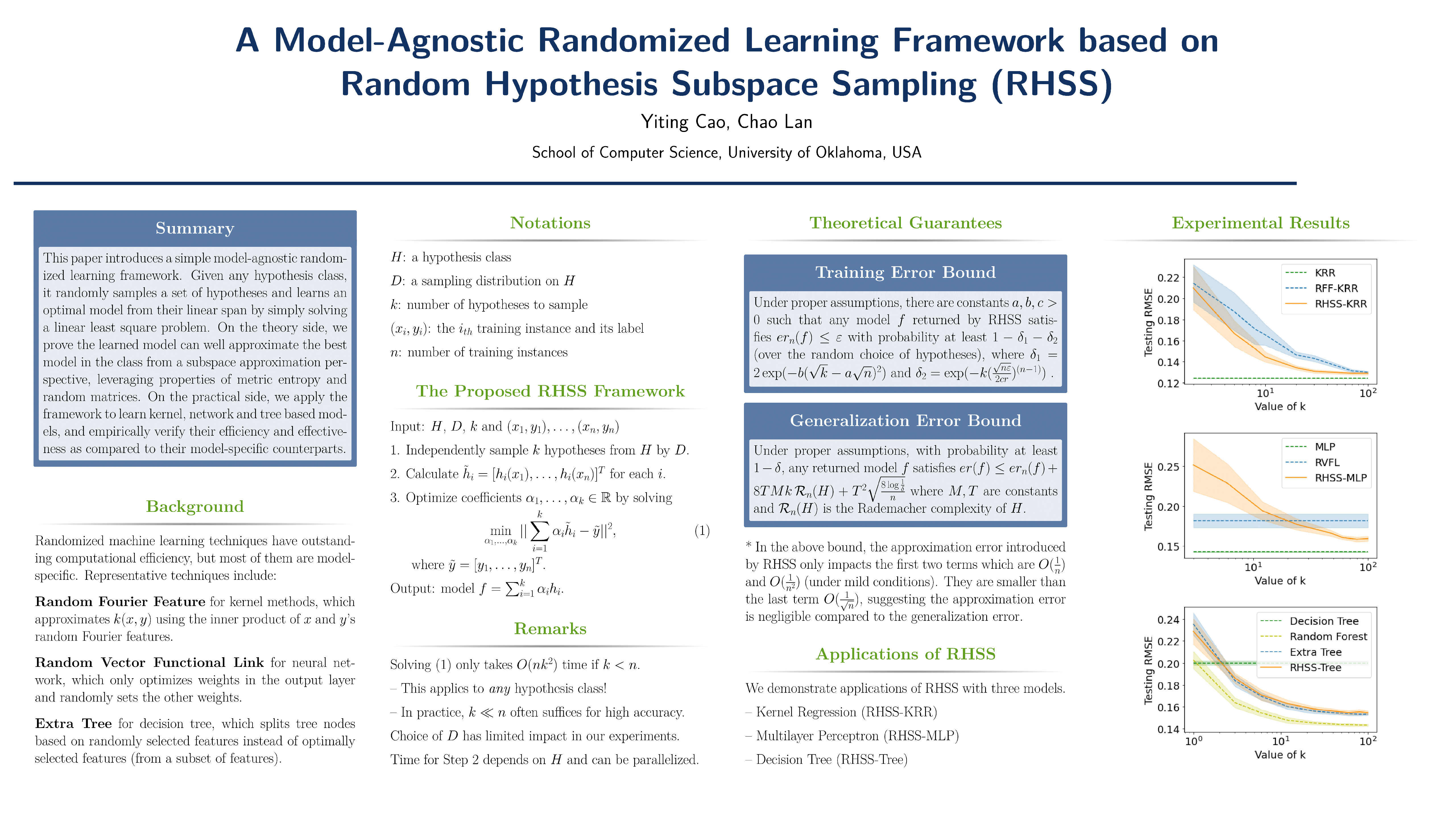
We propose a model-agnostic randomized learning framework based on Random Hypothesis Subspace Sampling (RHSS). Given any hypothesis class, it randomly samples $k$ hypotheses and learns a near-optimal model from their span by simply solving a linear least square problem in $O(n k^2)$ time, where $n$ is the number of training instances. On the theory side, we derive the performance guarantee of RHSS from a generic subspace approximation perspective, leveraging properties of metric entropy and random matrices. On the practical side, we apply the RHSS framework to learn kernel, network and tree based models. Experimental results show they converge efficiently as $k$ increases and outperform their model-specific counterparts including random Fourier feature, random vector functional link and extra tree on real-world data sets.
Chat is not available.
Successful Page Load