DRIBO: Robust Deep Reinforcement Learning via Multi-View Information Bottleneck
{kind=link}
Abstract
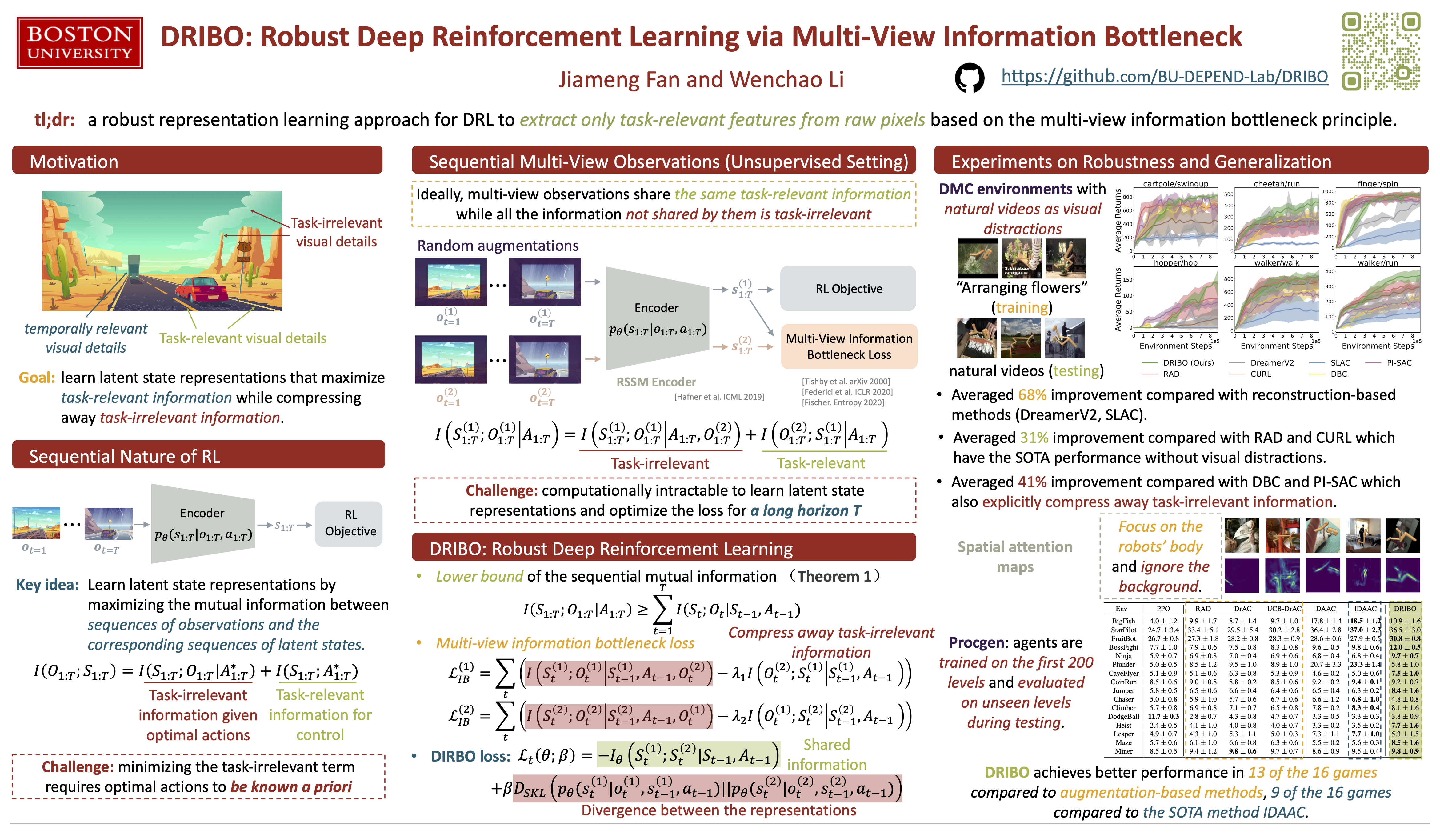
Deep reinforcement learning (DRL) agents are often sensitive to visual changes that were unseen in their training environments. To address this problem, we leverage the sequential nature of RL to learn robust representations that encode only task-relevant information from observations based on the unsupervised multi-view setting. Specif- ically, we introduce a novel contrastive version of the Multi-View Information Bottleneck (MIB) objective for temporal data. We train RL agents from pixels with this auxiliary objective to learn robust representations that can compress away task-irrelevant information and are predictive of task-relevant dynamics. This approach enables us to train high-performance policies that are robust to visual distractions and can generalize well to unseen environments. We demonstrate that our approach can achieve SOTA performance on a di- verse set of visual control tasks in the DeepMind Control Suite when the background is replaced with natural videos. In addition, we show that our approach outperforms well-established base- lines for generalization to unseen environments on the Procgen benchmark. Our code is open- sourced and available at https://github. com/BU-DEPEND-Lab/DRIBO.