Evolving Curricula with Regret-Based Environment Design
{kind=link}
Abstract
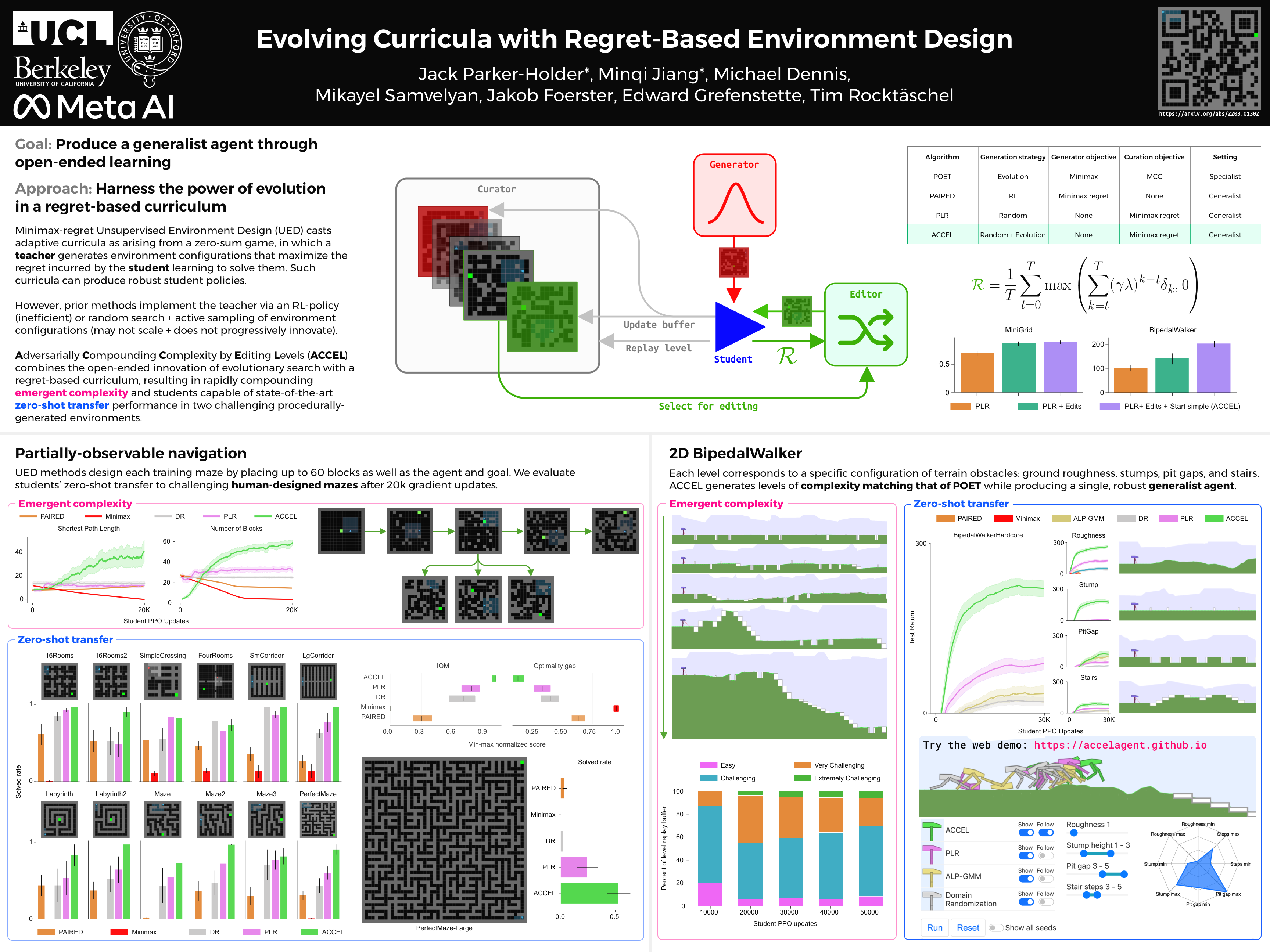
Training generally-capable agents with reinforcement learning (RL) remains a significant challenge. A promising avenue for improving the robustness of RL agents is through the use of curricula. One such class of methods frames environment design as a game between a student and a teacher, using regret-based objectives to produce environment instantiations (or levels) at the frontier of the student agent's capabilities. These methods benefit from theoretical robustness guarantees at equilibrium, yet they often struggle to find effective levels in challenging design spaces in practice. By contrast, evolutionary approaches incrementally alter environment complexity, resulting in potentially open-ended learning, but often rely on domain-specific heuristics and vast amounts of computational resources. This work proposes harnessing the power of evolution in a principled, regret-based curriculum. Our approach, which we call Adversarially Compounding Complexity by Editing Levels (ACCEL), seeks to constantly produce levels at the frontier of an agent's capabilities, resulting in curricula that start simple but become increasingly complex. ACCEL maintains the theoretical benefits of prior regret-based methods, while providing significant empirical gains in a diverse set of environments. An interactive version of this paper is available at https://accelagent.github.io.