Generative Trees: Adversarial and Copycat
Richard Nock ⋅ Mathieu Guillame-Bert
Keywords:
OPT: Convex
DL: Generative Models and Autoencoders
MISC: Unsupervised and Semi-supervised Learning
T: Optimization
T: Learning Theory
2022 Poster
{kind=link}
Abstract
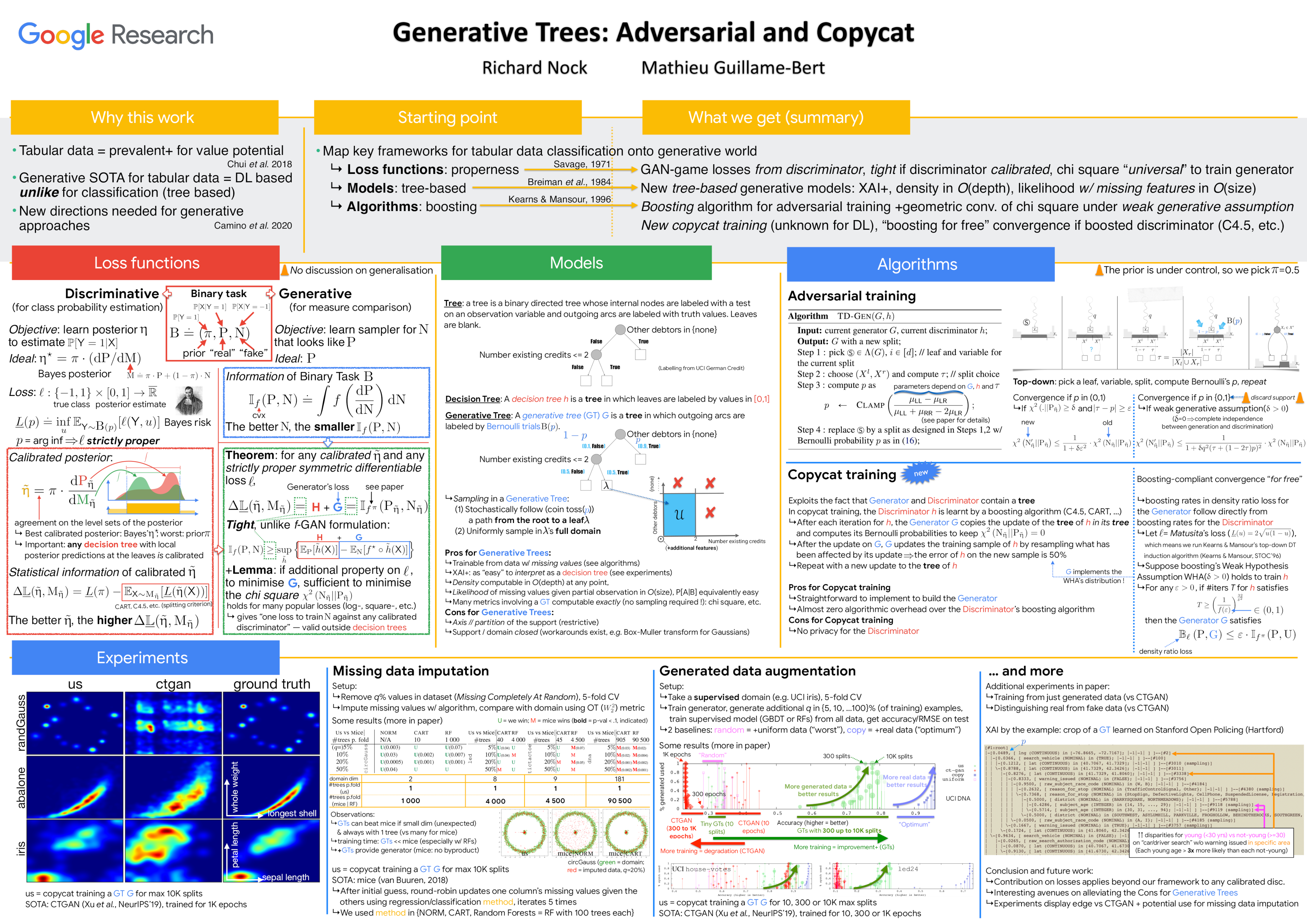
While Generative Adversarial Networks (GANs) achieve spectacular results on unstructured data like images, there is still a gap on \textit{tabular data}, data for which state of the art \textit{supervised learning} still favours decision tree (DT)-based models. This paper proposes a new path forward for the generation of tabular data, exploiting decades-old understanding of the supervised task's best components for DT induction, from losses (properness), models (tree-based) to algorithms (boosting). The \textit{properness} condition on the supervised loss -- which postulates the optimality of Bayes rule -- leads us to a variational GAN-style loss formulation which is \textit{tight} when discriminators meet a calibration property trivially satisfied by DTs, and, under common assumptions about the supervised loss, yields "one loss to train against them all" for the generator: the $\chi^2$. We then introduce tree-based generative models, \textit{generative trees} (GTs), meant to mirror on the generative side the good properties of DTs for classifying tabular data, with a boosting-compliant \textit{adversarial} training algorithm for GTs. We also introduce \textit{copycat training}, in which the generator copies at run time the underlying tree (graph) of the discriminator DT and completes it for the hardest discriminative task, with boosting compliant convergence. We test our algorithms on tasks including fake/real distinction and missing data imputation.
Chat is not available.
Successful Page Load